Posts about Hadoop

Hadoop about
May 26, 2021 10:00 0 Comment Hadoop
Hadoop, Hadoop, Paving, Big data, Hadoop, The basic principles of Hadoop's components, processing processes and key knowledge points are recorded, including HDFS, YARN, MapReduce, etc.

Introduction to Hadoop
May 26, 2021 10:00 0 Comment Hadoop
Hadoop - Introduction, Hadoop - Introduction, For, Not suitable, Hadoop architecture, Hadoop - Introduction, Hadoop can be operated on general commercial servers, with high fault tolerance, high reliability, high scalability and so on,

Hadoop HDFS
May 26, 2021 10:00 0 Comment Hadoop
Hadoop - HDFS, Hadoop - HDFS, Brief introduction, Architecture, Hadoop - HDFS, Brief introduction, Hadoop Distributed File System, Distributed File System, Architecture, Block blocks;, Basic storage units, the gene
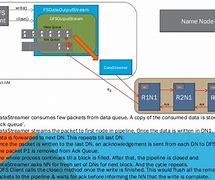
Hadoop writes the file
May 26, 2021 10:00 0 Comment Hadoop
HDFS - Write a file, HDFS - Write a file, HDFS - Write a file, 1. The client writes the file to the HDFS Client file on the local disk, 2. When the temporary file size reaches a block size, HD
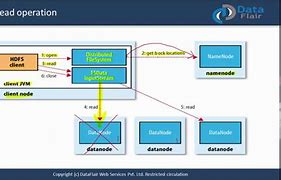
Hadoop reads the file
May 26, 2021 10:00 0 Comment Hadoop
HDFS - Read the file, HDFS - Read the file, HDFS - Read the file, The client sends a read request to NameNode, NameNode returns all the locks of the files and the DataNodes in which they are loc
Hadoop reliability
May 26, 2021 10:00 0 Comment Hadoop
HDFS - Reliability, HDFS - Reliability, 1. Redundant copy policy, 2. Rack strategy, 3. Heartbeat mechanism, 4. Safe mode, 5. The effect is the same, 6. Recycle bin, 7. Metadata protection, HDFS - Reliability, There are a few key points to hdFS reliability:, Redundant replica policy, Rack strategy, Heartbeat mechanism, Safe mode, The effe
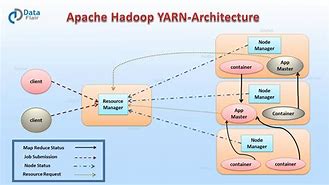
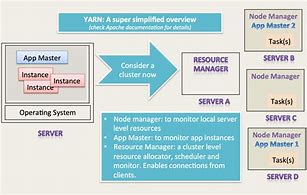
Hadoop YARN
May 26, 2021 11:00 0 Comment Hadoop
Hadoop Hadoop - YARN, Hadoop Hadoop - YARN, The old MapReduce architecture, YARN architecture, Architectural comparison, YARN basic process, Hadoop, Hadoop - YARN, The old MapReduce architecture, JobTracker: Responsible, for resource management, tracking resource consumption and availabilit
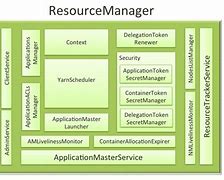
Hadoop ResourceManager
May 26, 2021 11:00 0 Comment Hadoop
YARN - ResourceManager, YARN - ResourceManager, Resource management, Task scheduling, The internal structure, YARN - ResourceManager, Responsible for global resource management and task scheduling, the entire cluster as a computing resource pool, only focus on
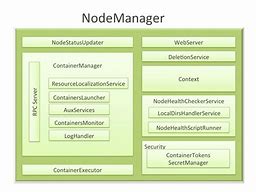
Hadoop NodeManager
May 26, 2021 11:00 0 Comment Hadoop
YARN - NodeManager, YARN - NodeManager, The internal structure, YARN - NodeManager, Container management under node nodes, Register with ResourceManager at startup and send a heartbeat message on a timely day, wait
Hadoop ApplicationMaster
May 26, 2021 11:00 0 Comment Hadoop
YARN - ApplicationMaster, YARN - ApplicationMaster, YARN - ApplicationMaster, Resource management and task monitoring for individual jobs, Description of the specific functions:, To calculate the applic
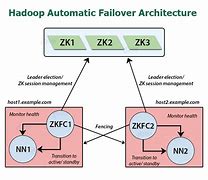
Hadoop Failover
May 26, 2021 11:00 0 Comment Hadoop
YARN - Failover, YARN - Failover, The type of failure, Failed processing, YARN - Failover, The type of failure, Program issues, The process crashed, Hardware issues, Failed processing, The task failed, Run-time exceptions or
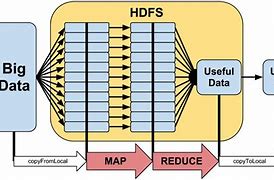
Hadoop MapReduce
May 26, 2021 11:00 0 Comment Hadoop
Hadoop - MapReduce, Hadoop - MapReduce, Brief introduction, Pattern, Basic processes, Detailed process, The process under the multi-node, The main process, Hadoop - MapReduce, Brief introduction, A distributed computing method specifies a Map (insulates the value of, A function that maps a set of key valu
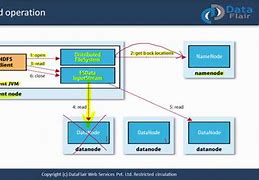
Hadoop reads the data
May 26, 2021 11:00 0 Comment Hadoop
MapReduce - Read data, MapReduce - Read data, InputFormat, InputSplit, RecordReader, Problem, MapReduce - Read data, The type of data read is determined by InputFormat, which is then split into One InputSplit, each InputSplit corresponds to a M
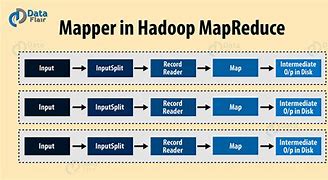
Hadoop Mapper
May 26, 2021 11:00 0 Comment Hadoop
MapReduce - Mapper, MapReduce - Mapper, MapReduce - Mapper, The main thing is to read each Key of InputSplit, value pair and process, public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {,
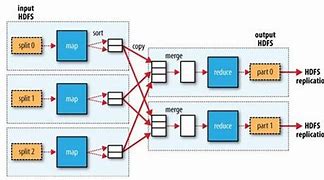
Hadoop Shuffle
May 26, 2021 12:00 0 Comment Hadoop
MapReduce - Shuffle, MapReduce - Shuffle, Map end, Reduce end, Tune in, Configuration, MapReduce - Shuffle, Sorting the results of Map and transferring them to Reduce for processing Map results are not stored directly to the hard disk, b