Hadoop writes the file
May 26, 2021 Hadoop
Table of contents
HDFS - Write a file
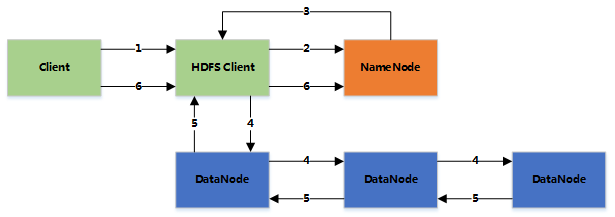
1. The client writes the file to the HDFS Client file on the local disk
2. When the temporary file size reaches a block size, HDFS client notifies NameNode and requests to write the file
3. NameNode creates a file in the HDFS file system and returns the block id and the list of DataNode to be written to the client
4. When the client receives this information, the temporary file is written to DataNodes
- 4.1 The client writes the contents of the file to the first DataNode (typically transferred in 4kb units)
- 4.2 When the first DataNode is received, the data is written to the local disk and also transferred to the second DataNode
- 4.3 And so on to the last DataNode, the data is copied between DataNode via pipeline
- 4.4 After DataNode receives the data, a confirmation is sent to the previous DataNode, and eventually the first DataNode returns the acknowledgement to the client
- 4.5 When the client receives an acknowledgement of the entire block, a final confirmation message is sent to NameNode
- 4.6 If writing to one DataNode fails, the data continues to be written to another DataNode. NameNode then finds another good DataNode to continue copying to ensure redundancy
- 4.7 Each block has a check code and is stored in a separate file to verify its integrity as it is read
5. After the file is finished (client closed), NameNode submits the file (then the file is visible, and if NameNode collapses before the commit, the file is lost.) fsync: Only information about the data is guaranteed to be written to NameNode, but there is no guarantee that the data has been written to DataNode)
Rack awareness (rack awareness)
The configuration file specifies the corresponding relationship between the rack name and DNS
Suppose the replication parameter is 3, one copy of the data is saved in the local rack when the file is written, and then two copies of the data are saved in the other rack (faster transfer within the same rack, improving performance)
The entire HDFS cluster is preferably load balanced in order to maximize the benefits of the cluster