Hadoop Shuffle
May 26, 2021 Hadoop
Table of contents
MapReduce - Shuffle
Sorting the results of Map and transferring them to Reduce for processing Map results are not stored directly to the hard disk, but use the cache to do some pre-sorting processing Map will call Comemer, compression, partitioning by key, sorting, etc., minimize the size of the results Each Map will notify Task when it is finished, and then Reduce can process it
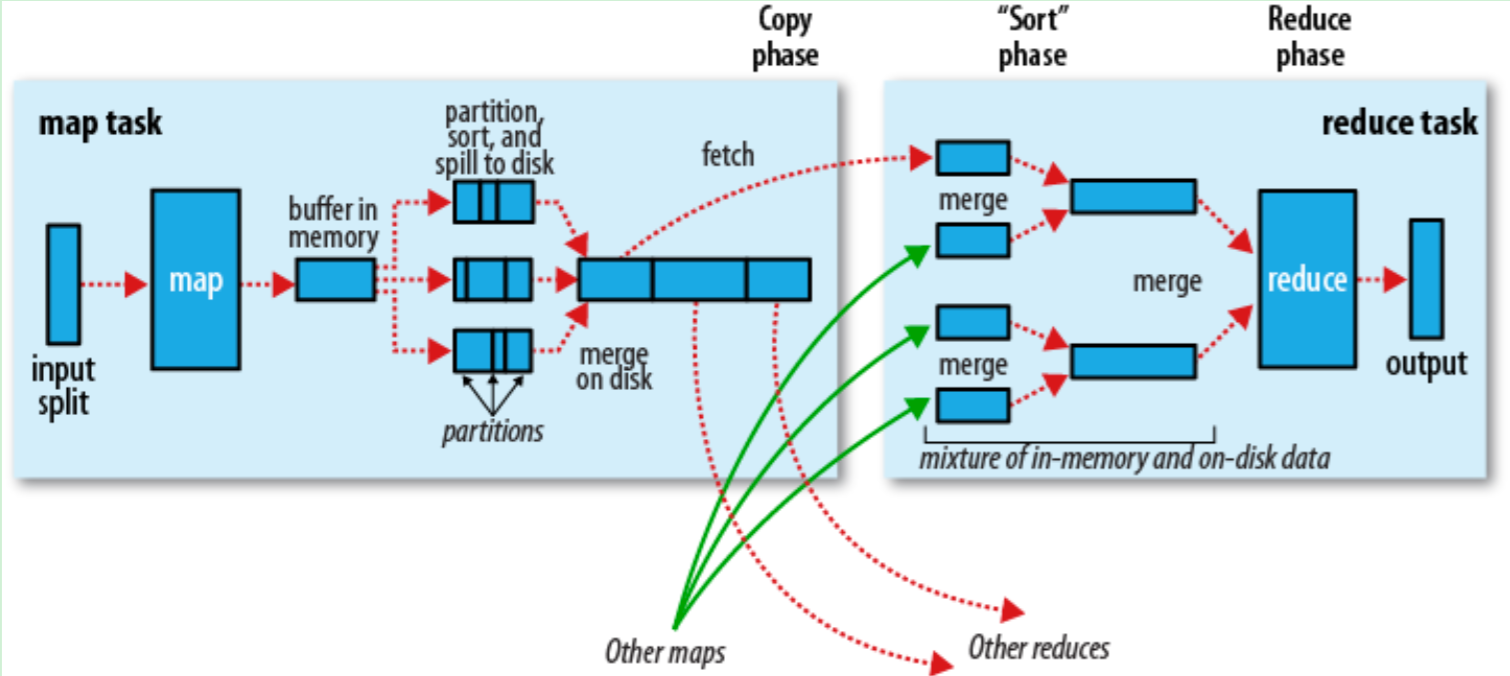
Map end
When the Map program starts producing results, it doesn't write directly to the file, but uses the cache to do some sorting pre-processing
Each Map task has a circular memory buffer (the default 100MB), and when the cached content reaches 80%, the background thread begins to write the content to the file, at which point the Map task can continue to output the results, but if the buffer is full, the Map task will have to wait
Write a file using the round-robin method. B efore writing to the file, partition the data according to Reduce. For each partition, the key is sorted in memory, and if a Protocol is configured, It is sorted and executed (combine can then reduce the amount of data written to files and transferred)
Each time the result reaches the threshold of the buffer, a file is created, and at the end of the Map, a large number of files may be generated. T hese files are merged and sorted before map is complete. If the number of files exceeds 3, the merge will run Comemer again (1, 2 files are not necessary)
If compression is configured, the files that are eventually written are compressed first, reducing the amount of data written and transferred
Once the Map is complete, notify task manager, at which point Reduce can begin copying the resulting data
Reduce end
Map's result files are stored on the local hard drive of the machine running the Map task
If map results are small, they are placed directly in memory, otherwise written to the file
At the same time, the background thread merges and sorts these files into a larger file (if the files are compressed, they need to be unzipped first)
When all Map results are copied and merged, the Reduce method is called
The Results are written to HDFS
Tune in
The general principle is to allocate as much memory as possible to shuffle, but only if you ensure that map and Reduce tasks have enough memory
For Map, the main thing is to avoid writing files to disk, for example, using Comemer to increase the value of io.sort.mb
For Reduce, it's about saving map results as much in memory as possible, and avoiding writing intermediate results to disk. By default, all memory is allocated to the Reduce method, which can be set to 0 and mapred.job.reduce.input.buffer.percent to 1.0 if the Reduce method does not consume much memory
The number of writes to disk can be monitored through Spilled records counter in task monitoring, but this value includes map and reduce
For the IO side, map results can be compressed while increasing the buffer size (io.file.buffer.size, default 4kb)
Configuration
| Property | The default | Describe |
|---|---|---|
| io.sort.mb | 100 | The size of the buffer used when mapping the output classification. |
| io.sort.record.percent | 0.05 | The remaining space is used to map the output itself to record. I n the 1. X removes this property after it is published. Random code is used to map all memory and record information. |
| io.sort.spill.percent | 0.80 | Scale is used for thresholds for mapping output memory buffers and record indexes. |
| io.sort.factor | 10 | The maximum number of merged streams when the files are classified. T his property is also used for reduce. The number is usually set to 100. |
| min.num.spills.for.combine | 3 | The minimum number of overflow files required for combined operation. |
| mapred.compress.map.output | false | Compress the mapping output. |
| mapred.map.output.compression.codec | DefaultCodec | The compression encoder required to map the output. |
| mapred.reduce.parallel.copies | 5 | The number of threads used to transmit the mapping output to reducer. |
| mapred.reduce.copy.backoff | 300 | The maximum amount of time, in seconds, during which time the reducer fails and repeated attempts are made to transmit |
| io.sort.factor | 10 | The maximum number of overflow files required for combined operation. |
| mapred.job.shuffle.input.buffer.percent | 0.70 | The random replication phase maps the stack size scale of the output buffer |
| mapred.job.shuffle.merge.percent | 0.66 | The scale at which the threshold of the mapped output buffer is used to initiate the merged output process and disk transfer |
| mapred.inmem.merge.threshold | 1000 | The number of thresholds used to start the mapped output for the merged output and disk transfer processes. Less than or equal to 0 means that there is no threshold, and overflow travel is managed separately by mapred.job.shuffle.merge.percent. |
| mapred.job.reduce.input.buffer.percent | 0.0 | Used to reduce the proportion of stack size of the memory map output, the in-memory mapping size must not exceed this value. This value can be increased if reducer requires less memory. |