Hadoop MapReduce
May 26, 2021 Hadoop
Table of contents
Hadoop - MapReduce
Brief introduction
A distributed computing method specifies a Map (insulates the value of A function that maps a set of key value pairs into a new set of key value pairs, specifying a common Reduce function to ensure that each of the key value pairs in all maps shares the same key group
Pattern
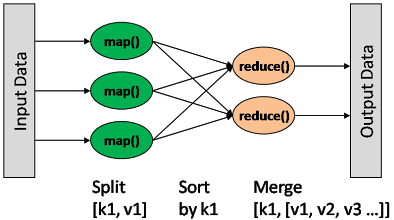
map: (K1, V1) → list(K2, V2) combine: (K2, list(V2)) → list(K2, V2) reduce: (K2, list(V2)) → list(K3, V3)
The Map output format must be the same as the Reduce input format
Basic processes
MapReduce mainly reads the file data, then Maps processing, then Reduce processing, and finally the results of the processing into the file
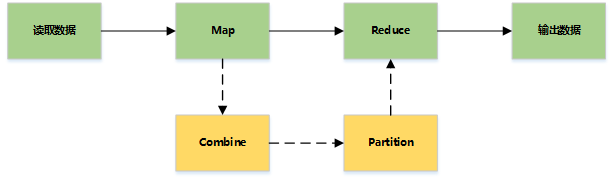
Detailed process
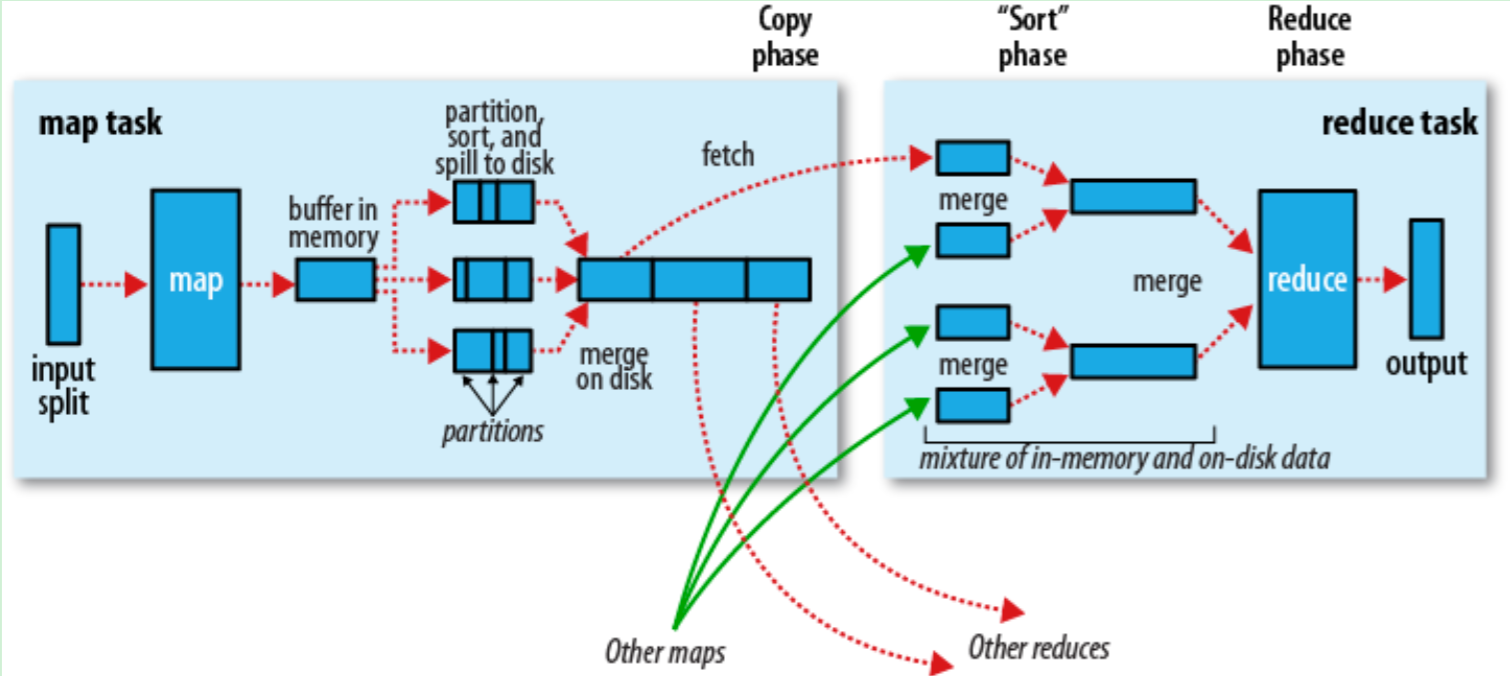
The process under the multi-node
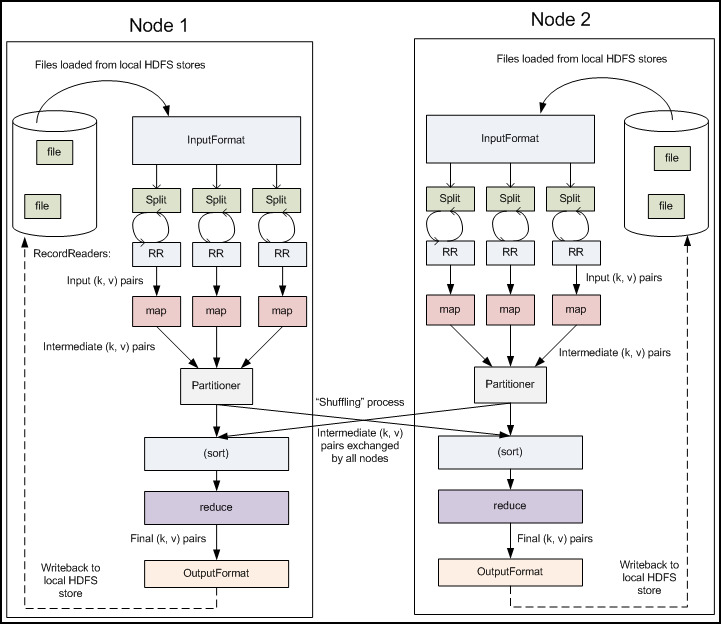
The main process

Map Side
Record reader
The record reader translates records generated by the input format, and the record reader is used to parse the data to the record and does not analyze the record itself. T he purpose of the record reader is to parse the data into records, but not to analyze the records themselves. I t transfers data to the mapper as a pair of key values. U sually the key is location information and the value is the data store block that make up the record. Custom records are beyond the scope of this article.
Map
The code provided by the user in the maper is called an intermediate pair. S pecific definitions of key values are prudent because they are important for the completion of distributed tasks. T he key determines the basis of the data classification, and the value determines the analysis information in the processor. T he design pattern of this book will show a lot of detail to explain how specific key values are selected.
Shuffle and Sort
The ruduce task starts with random and sorting steps. T his step is written to the output file and downloaded to the local computer. The data is sorted by keys to combine the equivalent keys.
Reduce
reduce uses grouped data as input. T his function passes the iterator of the key and the value associated with the key. T here are several ways to summarize, filter, or combine data. When the reduce function is complete, 0 or more key value pairs are sent.
The output format
The output format converts the final key value pair and writes to the file. B y default, keys and values are split by tab, and records are split by line breaks. A s a result, more output formats can be customized, and the final data is written to HDFS. Similar to record reading, custom output formats are not in the scope of this book.