Hadoop reads the data
May 26, 2021 Hadoop
Table of contents
MapReduce - Read data
The type of data read is determined by InputFormat, which is then split into One InputSplit, each InputSplit corresponds to a Map processing, and RecordReader reads the contents of InputSplit to Map
InputFormat
Determines the format in which the data is read, which can be a file or database, and so on
Function
- Verify that the job input is correct, such as format, etc
- Cutting the input file into logical splits, an InputSplit is assigned to a separate Map task
- Provides the RecordReader implementation, which reads the "K-V pair" in InputSplit for Mapper to use
Method
List getSplits(): Get input split calculated by the input file to solve the problem of data or file segmentation
RecordReader CreateRecordReader(): Create RecordReader to read data from InputSplit to solve the problem of reading data in a shrapder
Class structure
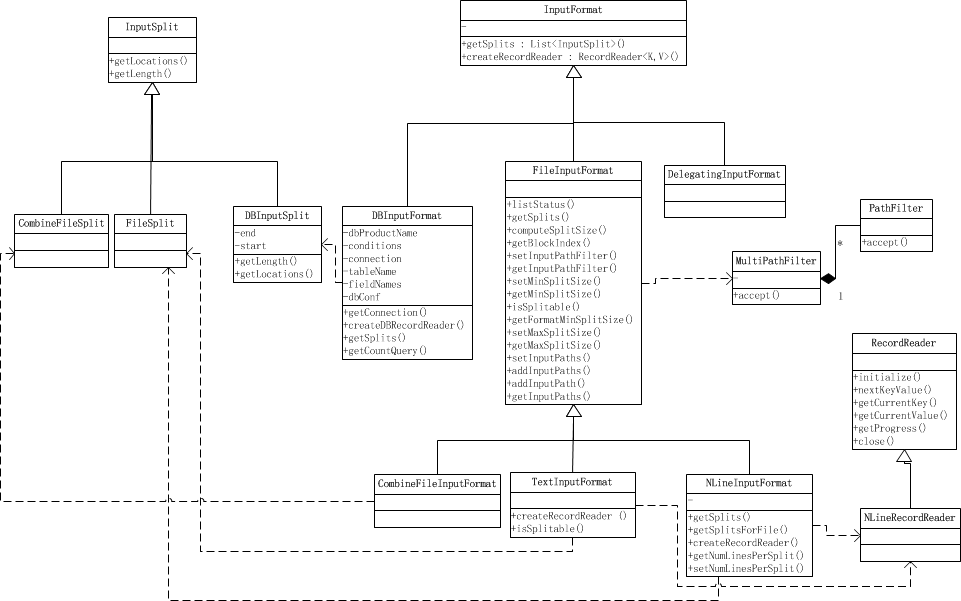
TextInputFormat: Every line in the input file is a record, Key is the byte offset of this line, and value is the content of this line
KeyValueTextInputFormat: Each line in the input file is a record, and the first separator character slices each line. T he content before the separator character is Key, followed by Value. Separator variables are set by key.value.separator.in.input.line variables, which default to the characters.
NLineInputFormat: As with TextInputFormat, but each block must be guaranteed to have and only N lines, mapred.line.input.format.linespermap property, default to 1
SequenceFileInputFormat: An InputFormat, slt;key, value, value, and custom for users to read character flow data. C haracter stream data is Hadoop's custom compressed binary data format. I t is used to optimize the data transfer process between the output of one MapReduce task and the input of another MapReduce task. </key,value>
InputSplit
Represents a logical shrapning, and does not really store data, but provides a way to slice the data
Split contains Location information for localization of data
An InputSplit gives a separate Map processing
public abstract class InputSplit {
/**
* 获取Split的大小,支持根据size对InputSplit排序.
*/
public abstract long getLength() throws IOException, InterruptedException;
/**
* 获取存储该分片的数据所在的节点位置.
*/
public abstract String[] getLocations() throws IOException, InterruptedException;
}RecordReader
Split The InputSplit into one by one, the value, the value, the pair to map processing, is also the actual file read separated object, the key, value.
Problem
How to handle a large number of small files
CombineFileInputFormat can package several Splits into one to avoid excessive Map tasks (because the number of Splits determines the number of Maps, the cost of creating and destroying a large number of Mapp Task will be huge)
How to calculate split
Usually a split is a block (FileInputFormat just splits a file large than block), which has the advantage of enabling Map to run local tasks on nodes that store current data without the need for cross-node task scheduling over the network
Control the size of the split by mapred.min.split.size, mapred.max.split.size, block.size
If the mapred.min.split.size is larger than the block size, two locks are composited into one split, so that some of the block data needs to be read over the network
If mapred.max.split.size is smaller than block size, a block is split into multiple splits, increasing the number of Map tasks (Map calculates and escalates the results, and turning off the current calculation to open a new split takes resources)
Get the file's path and block information on HDFS first, and then slice the file according to splitSize (splitSize , computeSplitSize) and the default splitSize is equal to the default value of blockSize (64m)
public List<InputSplit> getSplits(JobContext job) throws IOException {
// 首先计算分片的最大和最小值。这两个值将会用来计算分片的大小
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
// generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
FileSystem fs = path.getFileSystem(job.getConfiguration());
// 获取该文件所有的block信息列表[hostname, offset, length]
BlockLocation[] blkLocations = fs.getFileBlockLocations(file, 0, length);
// 判断文件是否可分割,通常是可分割的,但如果文件是压缩的,将不可分割
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
// 计算分片大小
// 即 Math.max(minSize, Math.min(maxSize, blockSize));
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
// 循环分片。
// 当剩余数据与分片大小比值大于Split_Slop时,继续分片, 小于等于时,停止分片
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize, blkLocations[blkIndex].getHosts()));
bytesRemaining -= splitSize;
}
// 处理余下的数据
if (bytesRemaining != 0) {
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining, blkLocations[blkLocations.length-1].getHosts()));
}
} else {
// 不可split,整块返回
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts()));
}
} else {
// 对于长度为0的文件,创建空Hosts列表,返回
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// 设置输入文件数量
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
LOG.debug("Total # of splits: " + splits.size());
return splits;
}How the data between the slices is handled
Split is split according to file size, while general processing is split according to separator, so there is bound to be a record spanning two splits

The solution is to read a record remotely as long as it is not the first split. Not all of the first split ignore the first record
public class LineRecordReader extends RecordReader<LongWritable, Text> {
private CompressionCodecFactory compressionCodecs = null;
private long start;
private long pos;
private long end;
private LineReader in;
private int maxLineLength;
private LongWritable key = null;
private Text value = null;
// initialize函数即对LineRecordReader的一个初始化
// 主要是计算分片的始末位置,打开输入流以供读取K-V对,处理分片经过压缩的情况等
public void initialize(InputSplit genericSplit, TaskAttemptContext context) throws IOException {
FileSplit split = (FileSplit) genericSplit;
Configuration job = context.getConfiguration();
this.maxLineLength = job.getInt("mapred.linerecordreader.maxlength", Integer.MAX_VALUE);
start = split.getStart();
end = start + split.getLength();
final Path file = split.getPath();
compressionCodecs = new CompressionCodecFactory(job);
final CompressionCodec codec = compressionCodecs.getCodec(file);
// 打开文件,并定位到分片读取的起始位置
FileSystem fs = file.getFileSystem(job);
FSDataInputStream fileIn = fs.open(split.getPath());
boolean skipFirstLine = false;
if (codec != null) {
// 文件是压缩文件的话,直接打开文件
in = new LineReader(codec.createInputStream(fileIn), job);
end = Long.MAX_VALUE;
} else {
// 只要不是第一个split,则忽略本split的第一行数据
if (start != 0) {
skipFirstLine = true;
--start;
// 定位到偏移位置,下次读取就会从偏移位置开始
fileIn.seek(start);
}
in = new LineReader(fileIn, job);
}
if (skipFirstLine) {
// 忽略第一行数据,重新定位start
start += in.readLine(new Text(), 0, (int) Math.min((long) Integer.MAX_VALUE, end - start));
}
this.pos = start;
}
public boolean nextKeyValue() throws IOException {
if (key == null) {
key = new LongWritable();
}
key.set(pos);// key即为偏移量
if (value == null) {
value = new Text();
}
int newSize = 0;
while (pos < end) {
newSize = in.readLine(value, maxLineLength, Math.max((int) Math.min(Integer.MAX_VALUE, end - pos), maxLineLength));
// 读取的数据长度为0,则说明已读完
if (newSize == 0) {
break;
}
pos += newSize;
// 读取的数据长度小于最大行长度,也说明已读取完毕
if (newSize < maxLineLength) {
break;
}
// 执行到此处,说明该行数据没读完,继续读入
}
if (newSize == 0) {
key = null;
value = null;
return false;
} else {
return true;
}
}
}