The Python reptile entry case ---- voice broadcast weather forecast
May 31, 2021 Article blog
Table of contents
Hello, hello, I'm your dear w3cschool editor, and today I'd like to share with you a small case of Python reptiles getting started---- voice-broadcast weather forecast.
The function of this case is to use reptiles to crawl weather information in an area and print out voice broadcasts.
First, pre-preparation
The libraries to be used in this case are: requests, lxml, pyttsx3, which can be installed via the cmd command into the command prompt interface:
pip install requests
pip install lxml
pip install pyttsx3
Requests are more convenient than urllib and save us a lot of work. In a word (after using requests, you're basically reluctant to use urllib), requests are the easiest HTTP library that Python implements, and reptiles are recommended to use the requests library.
lxml is a parsing library for Python, supports HTML and XML parsing, supports XPath parsing, and is highly efficient.
pyttsx3 is a Python package that converts text into speech, and unlike other Python packages, pyttsx3 can really convert text to speech. The basic usage is as follows:
import pyttsx3
test = pyttsx3.init()
test.say('hello w3cschool!')
# 关一, if there is no, the voice will not play
test.runAndWait()
If you're a linux system, pyttsx3 text-to-speech doesn't work. T hen you may also need to install espeak, ffmpeg, and libespeak1. The installation command is as follows:
sudo apt update && sudo apt install espeak ffmpeg libespeak1
A reptile is something about crawling a Web page, and understanding HTML can help you better understand the structure, content, and so on.
TCP/IP protocols, HTTP protocols, it's a good idea to understand and understand the basic meaning, so you can understand the basics of network requests and network transport.
Second, detailed steps
1, get request the destination URL
We first import the requests library and then use it to get the target page, and we are asking for Xiamen weather in the weather website.
import requests
# Send a request to the target URL address, return a Response object
resp = requests.get('https://www.tianqi.com/xaimen/')
# .Text is the page HTML of the Response object
print(resp.text)
Of course, with these three lines of code alone, it is very likely that the crawl can not get the page, showing 403, what does this mean?
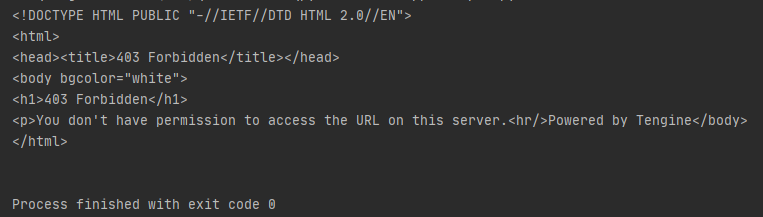
A 403 error is a common type of network error that indicates that a resource is unavailable and the server knows the customer's request but refuses to process it.
This is because the reptiles we write without adding a request header for access send a Python crawl request on its own, and most sites have anti-reptile mechanisms that do not allow site content to be crawled by crawlers.
So, is that inexplicable? T hat's definitely impossible, as the saying goes, there's policy, there's countermeasures, we want the target server to be corresponding, then we've got to camouflage the reptiles. I n our small case this time, we'll add the commonly used User-Agent field to disguise it.
So, change the code we had before and masquerade the reptile as a browser request, as follows:
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}
# Send a request to the target URL address, return a Response object
resp = requests.get('https://www.tianqi.com/xaimen/',headers=headers)
# .Text is the page HTML of the Response object
print(resp.text)
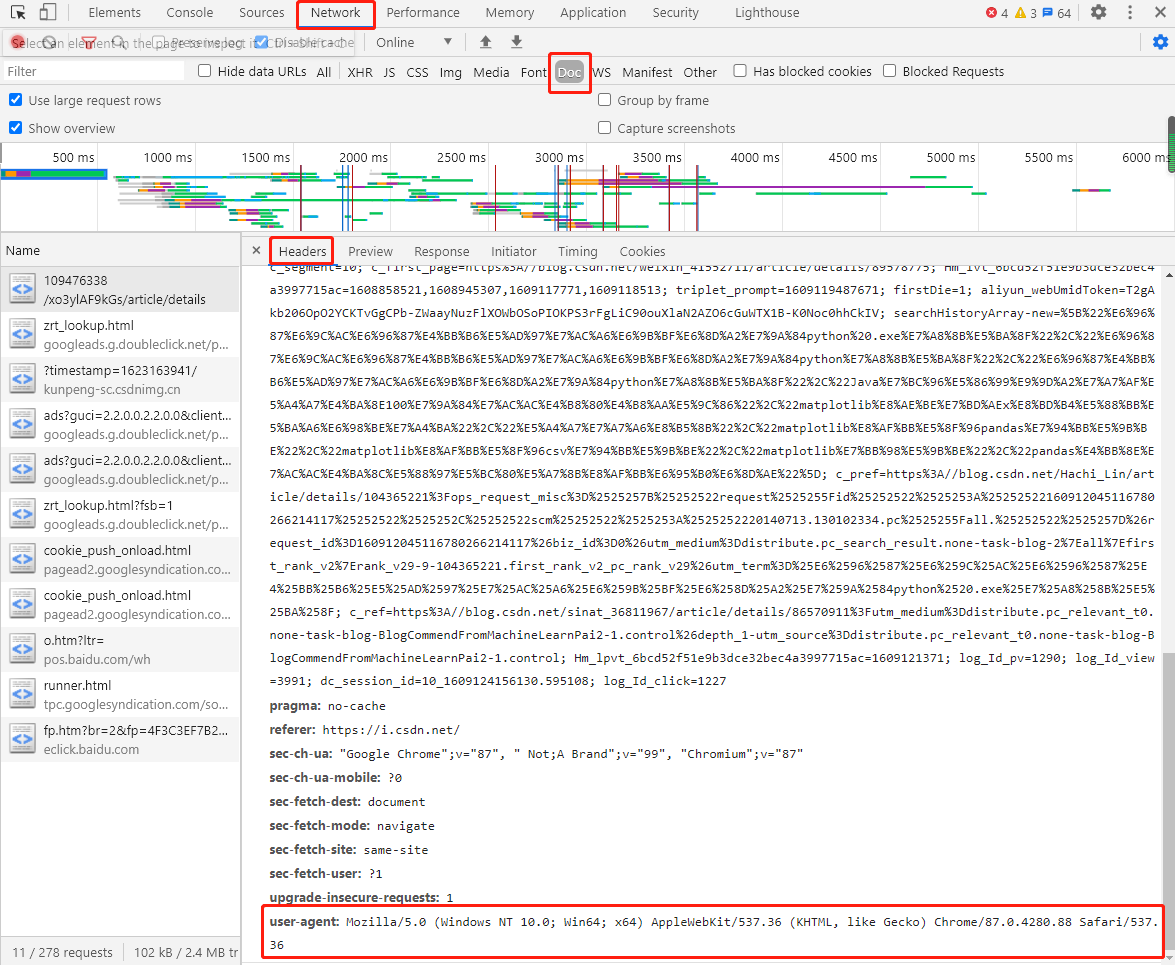
A little buddy is about to ask: How did the User-Agent field come about? H ere we take Chrome as an example, first open a web page, press the keyboard F12 or right-click in the blank to select "check", then refresh the page, click "Network" and then click "Doc", click Headers, in the information bar to view Request Headers User-Agent field, copy directly, stick to the compiler can be used, note to add in the form of a dictionary.
2, lxml.etree parsing web pages
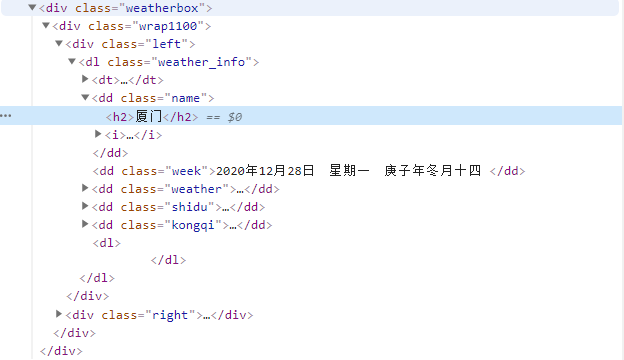
We crawled from the web page to get the data cluttered, only part of which is what we really want to get data, for example in this case we just need the weather details of Xiamen City on the web page, as shown in the figure:
So how do we extract it? I t's time to use lxml.etree.
Looking at the structure of the web page, we can see that all the weather information we need is under the custom list of "dl weather_info class" and we can parse that information simply by adding the following code after the previous code:
html = etree.HTML(html)
html_data = html.xpath("//d1[@class='weather_info']//text()")
Let's try printing the information and get the information as shown:

It is not difficult to find that the information obtained and the information we want is not very consistent, the page spaces and line breaks are also let us extract, the resulting object is also the list type.
So, here's what we need to do next:
TXT = "Welcome to the Weather Broadcast Assistant"
for data in html_data:
txt += data
It's not hard to print again and find that all the information we need is there, and it looks nice, but what's lacking in the U.S. and China is that the "Switch City" is still there, and we don't want it.
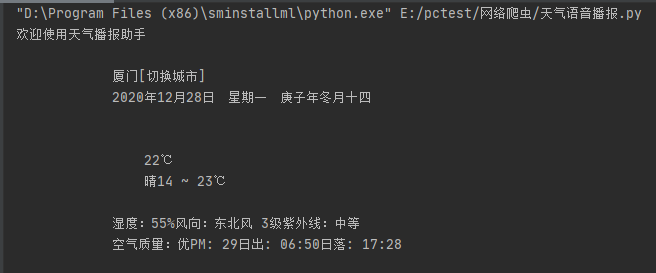
So what do we do, let's replace it with a string method.
TXT = txt.replace ('[Switch City]', '')
Third, pyttsx3 broadcast weather information
At this point, all the data we want has been crawled down and processed and saved in the txt variable, so let him read it out now, and it's time for pyttsx3 to come to the table, with the following code:
test = pyttsx3.init()
test.say(txt)
test.runAndWait()
At this point, our little case is done and good lessons are recommended: Python static reptiles, Python Scrapy network crawlers.
Step by step groping, to the realization of functions, in which the fun and sense of achievement, I believe that small partners are very happy.
Finally: Full source code on:
import requests
import pyttsx3
from lxml import etree
url = 'https://www.tianqi.com/xiamen/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}
Resp = Requests.get (URL = URL, Headers = Headers) # Send a request to the target URL address, returns a response object
HTML = Resp.Text # .text is the page HTML of the Response object
html = etree.HTML(html)
html_data = html.xpath("//dl[@class='weather_info']//text()")
TXT = "Welcome to the Weather Broadcast Assistant"
for data in html_data:
txt += data
print(txt)
TXT = txt.replace ('[Switch City]', '')
TXT + = '\ n broadcast is completed!Thanks!'
print(txt)
test = pyttsx3.init()
test.say(txt)
test.runAndWait()