The basic concept of Nginx
May 23, 2021 Nginx Getting started
Table of contents
The basic concept of Nginx
connection
In Nginx, connection is the encapsulation of a tcp connection, which includes the socket of the connection, reading events, and writing events. W ith the connection encapsulated by Nginx, we can easily use Nginx to handle connection-related things, such as establishing connections, sending and receiving data, and so on. T he processing of http requests in Nginx is based on connection, so Nginx can be used not only as a web server, but also as a mail server. Of course, with the connection provided by Nginx, we can work with any back-end service.
Combined with the lifecycle of a tcp connection, let's look at how Nginx handles a connection. F irst, Nginx resolves the configuration file, gets the port and ip address that needs to be monitored, and then in Nginx's master process, initializes the monitoring socket (create socket, set up options such as addreuse, bind to the specified ip address port, then listen), and then fork out multiple sub-processes, which then compete for a new connection. A t this point, the client can initiate a connection to Nginx. W hen the client and the service side make a connection by shaking hands three times, one of Nginx's sub-processes will accept successfully, get the socket of the established connection, and then create the Nginx encapsulation of the connection, the ngx_connection_t structure. N ext, set up the read-write event handler and add read-write events to exchange data with the client. Finally, Nginx or the client comes to actively turn off the connection, and a connection ends.
Of course, Nginx can also be used as a client to request data from other servers, such as the upstream module, where connections created with other servers are encapsulated in ngx_connection_t. A s a client, Nginx gets a ngx_connection_t structure, then creates the socket, and sets the properties of the socket (such as non-blocking). Then call the connection by adding a read/write event, call connect/read/write, finally turn off the connection, and release the ngx_connection_t.
In Nginx, each process has a maximum limit of the number of connections, which is different from the system's limit on fd. I
n the operating
ulimit -n
we can get the maximum number of fds that a process can open, that is, nofile, because each socket connection takes up one fd, so this also limits the maximum number of connections to our process, and of course directly affects the maximum number of co-operations that our program can support, and when the fd is used up, the socket will fail. N
ginx sets the maximum number of connections worker_connectons process by setting the number of connections for each process. I
f the value is greater than nofile, the actual maximum number of connections is nofile, and Nginx will have a warning. N
ginx is implemented through a connection pool, each worker process has a separate connection pool, the size of which is worker_connections. W
hat's saved in the connection pool here isn't really a connection, it's just an array of worker_connections-sized ngx_connection_t structures.
Also, Nginx saves all idle ngx_connection_t through a list free_connections, and each time a connection is acquired, one is obtained from the idle connection list, which is used up and then put back into the idle connection list.
Here, many people misunderstand worker_connections this parameter, which is the maximum that Nginx can make a connection. O
therwise, this value represents the maximum number of connections that each worker process can establish, so the maximum number of connections that an Nginx can establish should
worker_connections * worker_processes
O
f course, here's the maximum number of connections that can be supported for HTTP request local resources
worker_connections * worker_processes
and if HTTP is the reverse proxy, the maximum converse number should
worker_connections * worker_processes/2
Because as a reverse proxy server, each converse establishes a connection to the client and a connection to the back-end service, consuming two connections.
Well, we said earlier that after a client connects over, multiple idle processes will compete for this connection, it is easy to see that this competition will lead to unfair, if a process gets more opportunities to accept, its idle connection is quickly used up, if you do not do some control in advance, when accept to a new tcp connection, because you can not get an idle connection, and can not transfer this connection to other processes, will eventually lead to this tcp connection can not be processed, I t's stopped. O bviously, this is unfair, some processes have free connections, but no processing opportunities, and some processes because there is no spare connection, but artificially discard the connection. S So, how to solve this problem? F irst, Nginx has to turn on the accept_mutex option, at which point only the process that gets accept_mutex will add the accept event, which means that Nginx controls whether the process adds the accept event. N ginx uses a variable called ngx_accept_disabled to control whether to compete for accept_mutex locks. I n the first piece of code, calculate the value of ngx_accept_disabled, which is one-eighth of the total number of connections for the Nginx single process, minus the number of free connections left, and the resulting ngx_accept_disabled has a rule that when the number of remaining connections is less than one-eighth of the total number of connections, the value is greater than 0, and the smaller the number of connections remaining, the higher the value. L ooking at the second piece of code, when ngx_accept_disabled is greater than 0, you don't try to get a accept_mutex lock, and you subtract ngx_accept_disabled by 1, so each time you execute here, you subtract 1 until it's less than 0. N ot getting a accept_mutex lock is tantamount to giving up the opportunity to acquire a connection, and it is clear that when there are fewer free connections, the greater the ngx_accept_disable, and the more chances are available, the greater the chance that other processes will acquire the lock. Without accept, your connections are controlled, and the connection pools of other processes are utilized, so that Nginx controls the balance of multi-process connections.
ngx_accept_disabled = ngx_cycle->connection_n / 8
- ngx_cycle->free_connection_n;
if (ngx_accept_disabled > 0) {
ngx_accept_disabled--;
} else {
if (ngx_trylock_accept_mutex(cycle) == NGX_ERROR) {
return;
}
if (ngx_accept_mutex_held) {
flags |= NGX_POST_EVENTS;
} else {
if (timer == NGX_TIMER_INFINITE
|| timer > ngx_accept_mutex_delay)
{
timer = ngx_accept_mutex_delay;
}
}
}Well, the connection is introduced here first, the purpose of this chapter is to introduce the basic concept, know what the connection in Nginx is on the line, and the connection is a relatively advanced usage, in the later module development advanced section will have a special section to explain the connection and the implementation and use of events.
request
In this section we say request, in Nginx we mean http requests, specifically the data structure in Nginx is ngx_http_request_t. n gx_http_request_t is encapsulating an http request. We know that an http request contains the request line, the request header, the request body, the response line, the response header, the response body.
Http requests are typical request-response types of network protocols, while http is a text protocol, so we are analyzing request lines with request heads, as well as output response lines and response heads, often one line at a time. I f we write an http server ourselves, the client usually sends a request after a connection is established. T hen we read a row of data and analyze the method, uri, and other information contained http_version row. T he request header is then processed one line at a time, and the request body is decided based on the information of the request method and the request header, as well as the length of the request body, and then read the request body. W hen we get the request, we process the request to generate the data that needs to be output, and then generate the response row, the response header, and the response body. A fter the response is sent to the client, a complete request is processed. O f course, this is the simplest way to handle webserver, in fact, Nginx does the same, but there are a few small differences, for example, when the request head read is complete, the request processing began. Nginx ngx_http_request_t data related to the output response of the resolution request.
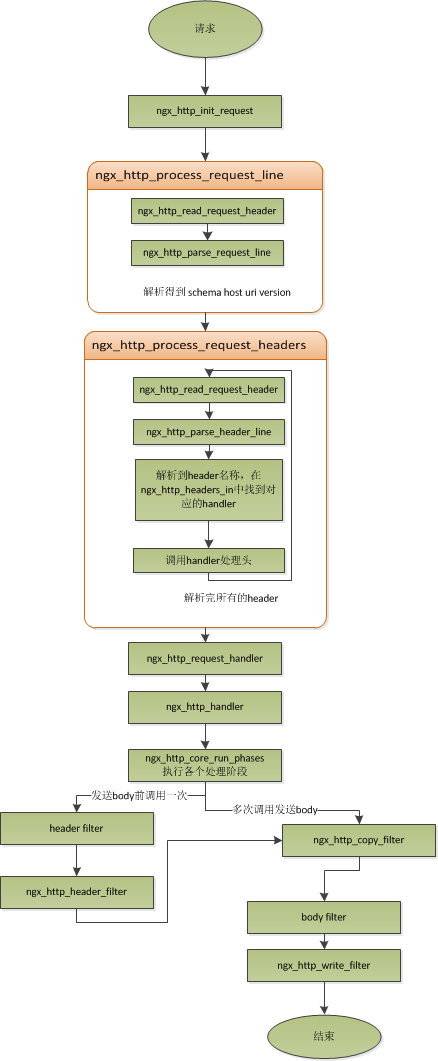
Next, let's briefly talk about how Nginx handles a complete request. F or Nginx, a request starts with ngx_http_init_request, in which the read event is set to ngx_http_process_request_line, that is, the next network event is executed by ngx_http_process_request_line. F rom ngx_http_process_request_line name of the request, we can see that this is to process the request line, just as we said earlier, the first thing to process the request is to process the request line is consistent. T he ngx_http_read_request_header data is read by using the file. T hen call the ngx_http_parse_request_line function to resolve the request line. F or efficiency, Nginx uses a state machine to parse request lines, and instead of using string comparisons directly for method comparisons, it converts four characters into an integer and then compares them at once to reduce the number of instructions for cpu, as mentioned earlier. M any people may be well aware that a request line contains the requested method, uri, version, but do not know that in fact in the request line, it can also contain host. F or example, a request line such as GET http://www.taobao.com/uri HTTP/1.0 is also legal, and host is www.taobao.com, at which point Nginx ignores the host domain in the request header and looks for the virtual host based on this in the request row. I n addition, for http0.9 version, request headers are not supported, so this is also a special treatment. T herefore, when the request header is parsed later, the protocol versions are 1.0 or 1.1. The parameters to which the entire request line resolves are saved to ngx_http_request_t structure.
After the request line is resolved, Nginx sets the handler of the read event to ngx_http_process_request_headers, and subsequent requests are read and parsed in ngx_http_process_request_headers. N gx_http_process_request_headers function is used to read the request header, just like the request line, or to call ngx_http_read_request_header to read the request header, to call ngx_http_parse_header_line to resolve a row of request headers, and to the request header to save to ngx_http_request_t the headers_in of the headers_in I n , headers_in is a list structure that holds all request heads. S ome requests in HTTP require special processing, and these request heads and request handlers are stored in a mapping table, ngx_http_headers_in, and at initialization, a hash table is generated, and when each resolution to a request header is resolved, it is first found in this hash table, and if found, the appropriate handler is called to handle the request header. For example, the handler of the Host header is ngx_http_process_host.
When Nginx resolves to two carriage return line breaks, it indicates the end of the request header, and the ngx_http_process_request is called to handle the request. n gx_http_process_request sets the current connection's read and write event handler to ngx_http_request_handler, and then calls ngx_http_handler to really start processing a full http request. I It may be strange here that the read-write event handlers are ngx_http_request_handler, but in this function, read_event_handler or read_event_handler in ngx_http_request_t are called, depending on whether the current event is a read or write_event_handler. S ince at this point, our request header has been read, as previously said, Nginx's approach is not to read the request body first, so here we set read_event_handler to ngx_http_block_reading, that is, do not read the data. A As I said earlier, the real way to start processing data is in ngx_http_handler, which sets write_event_handler to ngx_http_core_run_phases and executes ngx_http_core_run_phases function. n gx_http_core_run_phases this function performs multi-stage request processing, Nginx divides the processing of an http request into multiple stages, then the function executes those stages to generate data. B Because ngx_http_core_run_phases will eventually produce data, it's easy to understand why it's important to set the handler for ngx_http_core_run_phases events. H ere, I briefly explain the call logic of the function, and we need to understand that the final call ngx_http_core_run_phases is to handle the request, and the resulting response header is placed in headers_out of ngx_http_request_t, which I'll talk about in the request processing process. T he various stages of Nginx process requests and end up calling filters to filter the data and process it, such as truncked transmission, gzip compression, and so on. T he filters here include header filters and body filters, which are processed on the response head or body. F ilter is a list structure with header filter and body filter, executing all filters in header filter before executing all filters in body filter. I n the last filter in the header filter, ngx_http_header_filter, this filter will traverse all the response heads, end up requiring the output of the response header in a continuous memory, and then call ngx_http_write_filter for output. n gx_http_write_filter is the last one in the body filter, so Nginx's first body information, after a series of body filters, ends with ngx_http_write_filter being called for output (shown).
It is important to note here that Nginx places the entire request header in a buffer, the size of which is set by configuring item client_header_buffer_size, and if the user's request header is too large for this buffer to install, Nginx will reassign a new, larger buffer to mount the request header, which can pass large_client_header_ b uffers to set, this large_buffer this set of buffers, such as configuration 48k, means that there are four 8k size buffers that can be used. N ote that in order to save the integrity of the request line or request header, a complete request line or request header needs to be placed in a continuous memory, so a complete request line or request header is saved only in a buffer. T his way, if the request row is larger than the size of a buffer, a 414 error is returned, and if a request header size is larger than a buffer size, 400 errors are returned. After understanding the values of these parameters and what Nginx actually does, in the scenario, we need to adapt them to the actual needs to optimize our program.
Working with flowcharts:
These are the life cycles of an http request in Nginx. Let's look at some of the concepts related to the request.
keepalive
Of course, in Nginx, long connections are also supported for http1.0 and http1.1. W hat is a long connection? W e know that http requests are based on the TCP protocol, so when the client makes a request, it needs to establish a TCP connection with the service side, and each TCP connection needs three handshakes to determine, if the network between the client and the service side is a little bit worse, these three interactions consume more time, and three interactions will bring network traffic. O f course, when the connection is disconnected, there are four interactions, which of course is not important for the user experience. W hile http requests are request-answered, if we can know the length of each request header and response body, then we can execute multiple requests on top of a connection, which is called a long connection, but only if we first determine the length of the request header and response body. F or requests, if the current request requires a body, such as a POST request, Nginx requires the client to specify content-length in the request header to indicate the size of the body, otherwise 400 errors are returned. T hat is, the length of the request body is determined, so what is the length of the response body? Let's start by looking at the determination of the length of the response body in the http protocol:
-
For the http1.0 protocol, if there is a content-length header in the response header, the length of the body is known by the length of content-length, and when the client receives the body, it can receive data at that length, which means that the request is complete. If there is no content-length header, the client receives the data until the service side actively disconnects, indicating that the body has received it.
- For the http1.1 protocol, if Transfer-encoding in the response header is a chunked transport, the body is a streaming output, and the body is divided into blocks, each beginning of which identifies the length of the current block, at which point the body does not need to be specified by length. I f it is a non-chunked transport and there is content-length, follow content-length to receive the data. Otherwise, if it is non-chunked and there is no content-length, the client receives the data until the service side actively disconnects.
From above, we can see that the length of the body is known except for http1.0 without content-length and http1.1 non-chunked without content-length. A t this point, when the service side has finished outputing body, you may consider using a long connection. T he ability to use long connections is also conditional. I f the connection in the client's request header is close, the client needs to turn off the long connection, if it is key-alive, the client needs to open the long connection, and if the client's request does not have the connection header, then according to the protocol, if it is http1.0, it is close by default and key-alive by default if it is http1.1. I f the result is keyalive, Nginx sets the currently connected keyalive property after outputing the response body, and waits for the client to request the next time. O f course, Nginx can't wait all the time, wouldn't it have been using this connection if the client hadn't been sending data? So when Nginx sets keyalive to wait for the next request, it also sets a maximum wait time, which is configured by option keepalive_timeout, and if configured to 0, it means turning off keyalive, at which point the http version, whether 1.1 or 1.0, the client's connection, whether close or keyalive, is forced to be close.
If the service side's final decision is keyalive on, the http header of the response will also contain a connection header domain with a value of "Keep-Alive" or "Close". I f the connection value is close, the connection is actively turned off after Nginx has responded to the data. T herefore, for Nginx, which has a large number of requests, turning off keyalive will eventually result in a more time-wait state socket. I n general, when a client has one access and needs multiple visits to the same server, the advantages of opening a keyalive, such as a picture server, are very large, usually a Web page contains many pictures. Turning on keyalive also significantly reduces the number of time-waits.
pipe
In http1.1, a new feature, pipeline, was introduced. S
o what is pipeline? P
ipeline is actually a pipeline job, which can be seen as a sublimation of keyalive, because pipeline is also based on long connections, the purpose is to make multiple requests using a connection. I
f the client wants to submit multiple requests, for keyalive, the second request must wait until the response to the first request is fully received before initiating, which is the same as the TCP's stop-wait protocol, which
2*RTT
F
or pipeline, clients do not have to wait until the first request has been processed to initiate a second request. T
he time to get two responses may be
1*RTT
N
ginx directly supports pipeline, but Nginx's handling of multiple requests in pipeline is not parallel, it is still one request after another, and only when the first request is processed, the client can initiate a second request. I
n this way, Nginx leverages pipeline to reduce the time it takes to wait for request header data for the second request after processing one request.
In fact, Nginx's approach is very simple, as mentioned earlier, Nginx will read the data in a buffer, so if Nginx after processing the previous request, if you find that there is data in the buffer, you think that the rest of the data is the beginning of the next request, and then the next request, otherwise set keyalive.
lingering_close
lingering_close, literally delaying the shutdown, that is, when Nginx wants to close the connection, it does not close the connection immediately, but instead closes the writing of the tcp connection and waits a while before turning off the connection read. W hy would you do that? L et's take a look at such a scenario. W hen Nginx receives a request from a client, it may be due to an error on the client or service side that immediately responds to the error message to the client, while Nginx responds to the error message in the case of a large division that needs to close the current connection. N ginx executes the write() system call to send the error message to the client, and the success of the write() system call does not mean that the data has been sent to the client and may still be in the write buffer of the tcp connection. T hen if you directly perform a close() system call to close the tcp connection, the kernel first checks whether there is any data sent by the client in the read buffer of tcp that is left in the kernel state that was not read by the user state process, and if there is a message sent to the client RST to close the data in the tcp connection drop write buffer, if not, waits for the data in the write buffer to be sent, and then disconnects after the normal 4 breakup messages. T herefore, when the data in the tcp write buffer appears in some scenarios it is not sent before the write() system call is executed to the close() system call, and there is data in the tcp read buffer that is not read, the close() system call causes the client to receive an RST message and not get the error message data sent by the service side. That client will certainly think, this server is so overbearing, moving on reset my connection, not even an error message.
In the above scenario, we can see that the key point is that the service side sends an RST package to the client, causing the data it sends to be ignored by the client. T herefore, the focus of the problem is to keep the service side from sending RST packages. C ome to think of it, we sent RST because we turned off the connection, we turned off the connection because we didn't want to process the connection anymore, and there wouldn't be any data generated. F For a full duplegong TCP connection, we just need to turn off the write, read can continue, we just need to throw away any data we read, so that when we turn off the connection, the client will not receive RST again. O f course, ultimately we still need to turn off this reading end, so we will set a timeout, after this time, turn off the reading, the client then send data to regardless, as the service side I will think, are so long, send you the wrong message should also read, and then slow is not my business, to blame you RP is not good. O f course, a normal client, after reading the data, shuts down the connection, and the service side shuts down the reader in a timeout. T These are exactly lingering_close we do. T he stack provides SO_LINGER option, which is configured to handle the lingering_close situation, but Nginx is a self-implemented lingering_close. l ingering_close exists to read the data from the remaining clients, so Nginx has a read timeout, set by the lingering_timeout option, and turn off the connection directly if no data is received within lingering_timeout. N ginx also supports setting a total read time, set by lingering_time, which is the time that Nginx retains the socket after it closes writing, and the client needs to send all the data within that time, otherwise Nginx will shut down the connection directly after that time. Of course, Nginx supports the option to configure whether lingering_close or not, lingering_close the option to configure.
So, in practice, should we open the lingering_close? There is no fixed recommendation, and as Maxim Dounin says, the main role of lingering_close is to maintain better client compatibility, but it requires more additional resources (such as connections that are always in use).
In this section, we introduce the basic concepts of connectivity and request in Nginx, and in the next section, we talk about the basic data structure.