Storm transactional topology
May 17, 2021 Storm getting Started
Table of contents
Transactional topology
As mentioned earlier in the book, with Storm programming, you can ensure that a message is processed successfully or failed by calling the ack and fail methods. B ut what happens when the metagroup is re-issued? H ow do you cut it without repeating it?
Storm 0.7.0 implements a new feature, the transactional topology, which enables messages to be semantically guaranteed that you can reseed messages in a secure manner and that they are processed only once. Without supporting transactional topology, you cannot complete calculations with accuracy, scalability, and assurance of error-free nature.
NOTE: Transactional topology is an abstract concept built on standard Storm spout and bolt.
Design
In a transactional topology, Storm processes tudals in parallel and sequentially. S
pout creates tups in batches for bolt processing in batches, which are called batches below. S
ome of these bolts submit processed batches in a strictly orderly manner as submitters.
This means that if you have two batches of five tuds per batch, two tudes will be processed in parallel by bolt, but the second tuogroup will not be committed until the commiter has successfully committed the first tuo.
NOTE:
When using transactional topology, data sources need to be able to resuscess batches, sometimes even multiple times. S
o make sure that your data source -- the spout you're connected to -- has this capability. T
his process can be described as two phases: the processing phase is purely parallel, with many batches processing at the same time. T
he submission phase Is a strictly ordered phase, and batch two is not submitted until batch one is successfully committed. T
ogether, these two phases are called a Storm transaction.
OTE:
Storm uses zookeeper to store transaction metadata, which by default is the zookeeper used by the topology.
You can modify the following two configuration parameter keys to specify the other zookeepers - transactional.zookeeper.servers and transactional.zookeyer.port.
Transactional practice
Let's create a Twitter analytics tool to understand how transactions work. W e read tweets from one Redis database, process them with a few bolts, and finally save the results in a list of another Redis database. T he result is a list of all topics and the number of times they appear in the tweets, a list of all users and the number of times they appear in the tweets, and a list of users that contain the topics and frequencies that initiated them. T opological diagram of this tool.
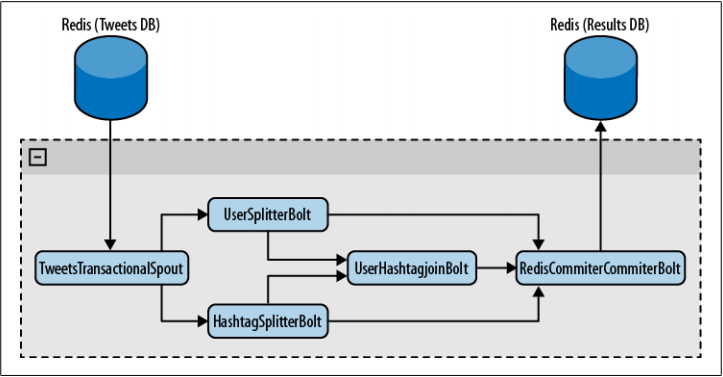
Figure Topology Overview
As you can see, TweetsTransactionalSpout connects to your tweet database and distributes batches to the topology. and HashTagSplitterBolt, two bolts, receive tups from spout. U serSplitterBolt parses the tweets and looks for the user -- words that begin with . . . and distributes those words to a custom data flow group called users. the words at the beginning of the hashtag from the tweet and distributes them to a custom data flow group called hashtags. The third bolt, UserHashtagJoinBolt, receives the two data stream groups mentioned earlier and calculates the number of topics within a tweet from a named user. To count and distribute the results, this is BaseBatchBolt (more on that later).
The last bolt, RedisCommitter Bolt, receives the data flow groups for the above three bolts. I t counts everything and saves all the results to redis when processing is done on a batch. This is a special bolt, called a commiter, which is explained more later in this chapter.
Build a topology with TransactionalTopologyBuilder, code as follows:
01
TransactionalTopologyBuilder builder=
02
new TransactionalTopologyBuilder("test", "spout", new TweetsTransactionalSpout());
03
04
builder.setBolt("users-splitter", new UserSplitterBolt(), 4).shuffleGrouping("spout");
05
buildeer.setBolt("hashtag-splitter", new HashtagSplitterBolt(), 4).shuffleGrouping("spout");
06
07
builder.setBolt("users-hashtag-manager", new UserHashtagJoinBolt(), r)
08
.fieldsGrouping("users-splitter", "users", new Fields("tweet_id"))
09
.fieldsGrouping("hashtag-splitter", "hashtags", new Fields("tweet_id"));
10
11
builder.setBolt("redis-commiter", new RedisCommiterBolt())
12
.globalGrouping("users-splitter", "users")
13
.globalGrouping("hashtag-splitter", "hashtags")
14
.globalGrouping("user-hashtag-merger"); Let's look at how to implement spout in a transactional topology.
Spout
The spout of a transactional topology is completely different from the standard spout.
1
public class TweetsTransactionalSpout extends BaseTransactionalSpout<TransactionMetadata>{ As you can see in this class definition, TweetsTransactionalSpout inherits baseTransactionalSpout with a paradigm. T he object of the specified pattern type is a collection of transaction metadata. It will be used later in the code to distribute batches from the data source.
In this example, TransactionMetadata defines it as follows:
01
public class TransactionMetadata implements Serializable {
02
private static final long serialVersionUID = 1L;
03
long from;
04
int quantity;
05
06
public TransactionMetadata(long from, int quantity) {
07
this.from = from;
08
this.quantity = quantity;
09
}
10
} Objects of this class maintain two properties, from and quantity, which are used to generate batches.
Spout's final implementation is three ways:
01
@Override
02
public ITransactionalSpout.Coordinator<TransactionMetadata> getCoordinator(
03
Map conf, TopologyContext context) {
04
return new TweetsTransactionalSpoutCoordinator();
05
}
06
07
@Override
08
public backtype.storm.transactional.ITransactionalSpout.Emitter<TransactionMetadata> getEmitter(Map conf, TopologyContext contest) {
09
return new TweetsTransactionalSpoutEmitter();
10
}
11
12
@Override
13
public void declareOutputFields(OuputFieldsDeclarer declarer) {
14
declarer.declare(new Fields("txid", "tweet_id", "tweet"));
15
} The getCoordinator method tells Storm the class used to coordinate the generation batch. ter, which is responsible for reading batches and distributing them to data flow groups in the topology. Finally, as you've done before, you need to declare the domain you want to distribute.
RQ class
To keep the example simple, we decided to encapsulate all operations on Redis with a class.
01
public class RQ {
02
public static final String NEXT_READ = "NEXT_READ";
03
public static final String NEXT_WRITE = "NEXT_WRITE";
04
05
Jedis jedis;
06
07
public RQ() {
08
jedis = new Jedis("localhost");
09
}
10
11
public long getavailableToRead(long current) {
12
return getNextWrite() - current;
13
}
14
15
public long getNextRead() {
16
String sNextRead = jedis.get(NEXT_READ);
17
if(sNextRead == null) {
18
return 1;
19
}
20
return Long.valueOf(sNextRead);
21
}
22
23
public long getNextWrite() {
24
return Long.valueOf(jedis.get(NEXT_WRITE));
25
}
26
27
public void close() {
28
jedis.disconnect();
29
}
30
31
public void setNextRead(long nextRead) {
32
jedis.set(NEXT_READ, ""+nextRead);
33
}
34
35
public List<String> getMessages(long from, int quantity) {
36
String[] keys = new String[quantity];
37
for (int i = 0; i < quantity; i++) {
38
keys[i] = ""+(i+from);
39
}
40
return jedis.mget(keys);
41
}
42
} Read each method carefully to make sure you understand their useful use.
Coordinator Coordinator
The following is the coordinator implementation for this example.
01
public static class TweetsTransactionalSpoutCoordinator implements ITransactionalSpout.Coordinator<TransactionMetadata> {
02
TransactionMetadata lastTransactionMetadata;
03
RQ rq = new RQ();
04
long nextRead = 0;
05
06
public TweetsTransactionalSpoutCoordinator() {
07
nextRead = rq.getNextRead();
08
}
09
10
@Override
11
public TransactionMetadata initializeTransaction(BigInteger txid, TransactionMetadata prevMetadata) {
12
long quantity = rq.getAvailableToRead(nextRead);
13
quantity = quantity > MAX_TRANSACTION_SIZE ? MAX_TRANSACTION_SIZE : quantity;
14
TransactionMetadata ret = new TransactionMetadata(nextRead, (int)quantity);
15
nextRead += quantity;
16
return ret;
17
}
18
19
@Override
20
public boolean isReady() {
21
return rq.getAvailableToRead(nextRead) > 0;
22
}
23
24
@Override
25
public void close() {
26
rq.close();
27
}
28
} It is worth mentioning that there is only one instance of the commiter throughout the topology. When you create a commiter instance, it reads a serial number from redis that starts at 1, which identifies the next tweet to read.
The first method is isReady. C all it before initializeTransaction to confirm that the data source is ready and readable. T his method should return true or false accordingly. I n this example, the number of tweets read is compared to the number read. T he difference between them is the number of readable tweets. If it is greater than 0, it means that there are still tweets that are not read.
Finally, perform initializeTransaction. A s you can see, it receives txid and prevMetadata as arguments. T he first argument is the transaction ID generated by Storm, which is identified as unique to the batch. PrevMetadata is the previous transaction metadata object generated by the coordinator.
In this example, first confirm how many tweets are readable. As soon as this is confirmed, create a Transaction Metaladata object that identifies the first tweet read and the number of tweets read.
Once the metadata object is returned, Storm saves it with txid in zookeeper. This ensures that in the event of a failure, Storm can resend the batch using a distributor ( Emitter, see below).
Emitter
The final step in creating a transactional spout is to implement the Emitter. The implementation is as follows:
01
public static class TweetsTransactionalSpoutEmitter implements ITransactionalSpout.Emitter<TransactionMetadata> {
02
03
</pre>
04
<pre> RQ rq = new RQ();</pre>
05
<pre> public TweetsTransactionalSpoutEmitter() {}</pre>
06
<pre> @Override
07
public void emitBatch(TransactionAttempt tx, TransactionMetadata coordinatorMeta, BatchOutputCollector collector) {
08
rq.setNextRead(coordinatorMeta.from+coordinatorMeta.quantity);
09
List<String> messages = rq.getMessages(coordinatorMeta.from, <span style="font-family: Georgia, 'Times New Roman', 'Bitstream Charter', Times, serif; font-size: 13px; line-height: 19px;">coordinatorMeta.quantity);
10
</span> long tweetId = coordinatorMeta.from;
11
for (String message : messages) {
12
collector.emit(new Values(tx, ""+tweetId, message));
13
tweetId++;
14
}
15
}
16
17
@Override
18
public void cleanupBefore(BigInteger txid) {}
19
20
@Override
21
public void close() {
22
rq.close();
23
}</pre>
24
<pre>
25
} The distributor reads the data from the data source and sends the data from the data flow group. T he distributor should be able to send the same batch for the same transaction id and transaction metadata. T his way, if a failure occurs while the batch is being processed, Storm is able to reuse the same transaction id and transaction metadata with the distributor and ensure that the batch has already been repeated. S torm increases the count of attempts in the TransactionAttempt object. This lets you know that the batch has been repeated.
EmitBatch is an important method here. I n this method, you get tweets from redis using the incoming metadata object, while increasing the number of read tweets maintained by redis. Of course, it also distributes the tweets it reads to the topology.
Bolts
First look at the standard bolts in this topology:
01
public class UserSplitterBolt implements IBasicBolt{
02
private static final long serialVersionUID = 1L;
03
04
@Override
05
public void declareOutputFields(OutputFieldsDeclarer declarer) {
06
declarer.declareStream("users", new Fields("txid","tweet_id","user"));
07
}
08
09
@Override
10
public Map<String, Object> getComponentConfiguration() {
11
return null;
12
}
13
14
@Override
15
public void prepare(Map stormConf, TopologyContext context) {}
16
17
@Override
18
public void execute(Tuple input, BasicOutputCollector collector) {
19
String tweet = input.getStringByField("tweet");
20
String tweetId = input.getStringByField("tweet_id");
21
StringTokenizer strTok = new StringTokenizer(tweet, " ");
22
HashSet<String> users = new HashSet<String>();
23
24
while(strTok.hasMoreTokens()) {
25
String user = strTok.nextToken();
26
27
//确保这是个真实的用户,并且在这个tweet中没有重复
28
if(user.startsWith("@") && !users.contains(user)) {
29
collector.emit("users", new Values(tx, tweetId, user));
30
users.add(user);
31
}
32
}
33
}
34
35
@Override
36
public void cleanup(){}
37
} As mentioned earlier in this chapter, UserSplitterBolt receives the metagroup, parses the tweet text, distributes the word ———— the tweeter user. The implementation of hashtagSplitterBolt is very similar.
01
public class HashtagSplitterBolt implements IBasicBolt{
02
private static final long serialVersionUID = 1L;
03
04
@Override
05
public void declareOutputFields(OutputFieldsDeclarer declarer) {
06
declarer.declareStream("hashtags", new Fields("txid","tweet_id","hashtag"));
07
}
08
09
@Override
10
public Map<String, Object> getComponentConfiguration() {
11
return null;
12
}
13
14
@Override
15
public void prepare(Map stormConf, TopologyContext context) {}
16
17
@Oerride
18
public void execute(Tuple input, BasicOutputCollector collector) {
19
String tweet = input.getStringByField("tweet");
20
String tweetId = input.getStringByField("tweet_id");
21
StringTokenizer strTok = new StringTokenizer(tweet, " ");
22
TransactionAttempt tx = (TransactionAttempt)input.getValueByField("txid");
23
HashSet<String> words = new HashSet<String>();
24
25
while(strTok.hasMoreTokens()) {
26
String word = strTok.nextToken();
27
28
if(word.startsWith("#") && !words.contains(word)){
29
collector.emit("hashtags", new Values(tx, tweetId, word));
30
words.add(word);
31
}
32
}
33
}
34
35
@Override
36
public void cleanup(){}
37
} Now look at the implementation of UserHashTagJoinBolt. T he first thing to note is that it's a BaseBatchBolt. T his means that the execute method manipulates the received yuan, but does not distribute the new group. When the batch is complete, Storm calls the finishBatch method.
01
public void execute(Tuple tuple) {
02
String source = tuple.getSourceStreamId();
03
String tweetId = tuple.getStringByField("tweet_id");
04
05
if("hashtags".equals(source)) {
06
String hashtag = tuple.getStringByField("hashtag");
07
add(tweetHashtags, tweetId, hashtag);
08
} else if("users".equals(source)) {
09
String user = tuple.getStringByField("user");
10
add(userTweets, user, tweetId);
11
}
12
} Now that you want to combine the user mentioned in the tweet to count all topics that appear, you need to join the two data flow groups created by the previous bolts. This is done in batches, and the finishBatch method is called when the batch processing is complete.
01
@Override
02
public void finishBatch() {
03
for(String user:userTweets.keySet()){
04
Set<String> tweets = getUserTweets(user);
05
HashMap<String, Integer> hashtagsCounter = new HashMap<String, Integer>();
06
for(String tweet:tweets){
07
Set<String> hashtags=getTweetHashtags(tweet);
08
if(hashtags!=null){
09
for(String hashtag:hashtags){
10
Integer count=hashtagsCounter.get(hashtag);
11
if(count==null){count=0;}
12
count++;
13
hashtagsCounter.put(hashtag,count);
14
}
15
}
16
}
17
for(String hashtag:hashtagsCounter.keySet()){
18
int count=hashtagsCounter.get(hashtag);
19
collector.emit(new Values(id,user,hashtag,count));
20
}
21
}
22
} This method calculates the number of times each pair of user-topics appears and generates and distributes dTs for it.
You can find and download the full code on GitHub. I don'https://github.com/storm-book/examples-ch08-transactional-topologies there's no code in this repository, and who knows where the code has trouble saying it. )
The submitter bolts
We've learned how batches are delivered in the topology through coordinators and distributors. In the topology, tudals in these batches are processed in parallel, without a specific order.
Coordinator bolts are a special class of batch bolts that implement IComh mitter or set up the submitter bolt by calling setCommiterBolt via Transactional Topology Builder. T he biggest difference between them and other batch bolts is that the submitter bolts' finishBatch method is executed when the commit is ready. T his occurs after all transactions have been successfully committed before. I n addition, the finishBatch method is executed sequentially. Therefore, if both transaction ID1 and transaction ID2 are executed at the same time, ID2 will not execute the finishBatch method until ID1 executes it without any errors.
Here is the implementation of this class
01
public class RedisCommiterCommiterBolt extends BaseTransactionalBolt implements ICommitter {
02
public static final String LAST_COMMITED_TRANSACTION_FIELD = "LAST_COMMIT";
03
TransactionAttempt id;
04
BatchOutputCollector collector;
05
Jedis jedis;
06
07
@Override
08
public void prepare(Map conf, TopologyContext context,
09
BatchOutputCollector collector, TransactionAttempt id) {
10
this.id = id;
11
this.collector = collector;
12
this.jedis = new Jedis("localhost");
13
}
14
15
HashMap<String, Long> hashtags = new HashMap<String,Long>();
16
HashMap<String, Long> users = new HashMap<String, Long>();
17
HashMap<String, Long> usersHashtags = new HashMap<String, Long>();
18
19
private void count(HashMap<String, Long> map, String key, int count) {
20
Long value = map.get(key);
21
if(value == null){value = (long)0;}
22
value += count;
23
map.put(key,value);
24
}
25
26
@Override
27
public void execute(Tuple tuple) {
28
String origin = tuple. getSourceComponent();
29
if("sers-splitter".equals(origin)) {
30
String user = tuple.getStringByField("user");
31
count(users, user, 1);
32
} else if("hashtag-splitter".equals(origin)) {
33
String hashtag = tuple.getStringByField("hashtag");
34
count(hashtags, hashtag, 1);
35
} else if("user-hashtag-merger".quals(origin)) {
36
String hashtag = tuple.getStringByField("hashtag");
37
String user = tuple.getStringByField("user");
38
String key = user + ":" + hashtag;
39
Integer count = tuple.getIntegerByField("count");
40
count(usersHashtags, key, count);
41
}
42
}
43
44
@Override
45
public void finishBatch() {
46
String lastCommitedTransaction = jedis.get(LAST_COMMITED_TRANSACTION_FIELD);
47
String currentTransaction = ""+id.getTransactionId();
48
49
if(currentTransaction.equals(lastCommitedTransaction)) {return;}
50
51
Transaction multi = jedis.multi();
52
53
multi.set(LAST_COMMITED_TRANSACTION_FIELD, currentTransaction);
54
55
Set<String> keys = hashtags.keySet();
56
for (String hashtag : keys) {
57
Long count = hashtags.get(hashtag);
58
multi.hincrBy("hashtags", hashtag, count);
59
}
60
61
keys = users.keySet();
62
for (String user : keys) {
63
Long count =users.get(user);
64
multi.hincrBy("users",user,count);
65
}
66
67
keys = usersHashtags.keySet();
68
for (String key : keys) {
69
Long count = usersHashtags.get(key);
70
multi.hincrBy("users_hashtags", key, count);
71
}
72
73
multi.exec();
74
}
75
76
@Override
77
public void declareOutputFields(OutputFieldsDeclarer declarer) {}
78
} The implementation is simple, but there is a detail in finishBatch.
1
...
2
multi.set(LAST_COMMITED_TRANSACTION_FIELD, currentTransaction);
3
... The last transaction ID committed is saved from the database here. W hy would you do that? K eep in mind that if the transaction fails, Storm will repeat as many times as necessary. I f you're not sure that you've handled the transaction, you're going to have to figure it out, and the transaction topology is useless. So keep in mind that save the last committed transaction ID and check before submitting.
The transaction Spouts for the partition
It is common for a spout to read batches from a partitioned collection. I n the next example, you might have a lot of redis databases, and tweets might be stored separately in those redis databases. B y implementing IPartitionedTransactionalSpout, Storm provides tools to manage the state of each partition and ensure replay capabilities.
Let's modify TweetsTransactionalSpout so that it can handle data partitions.
First, inherit BasePartitioned TransactionalSpout, which implements IPartitionedTransactionalSpout.
1
public class TweetsPartitionedTransactionalSpout extends
2
BasePartitionedTransactionalSpout<TransactionMetadata> {
3
...
4
} Then tell Storm who your coordinator is.
01
public static class TweetsPartitionedTransactionalCoordinator implements Coordinator {
02
@Override
03
public int numPartitions() {
04
return 4;
05
}
06
07
@Override
08
public boolean isReady() {
09
return true;
10
}
11
12
@Override
13
public void close() {}
14
} In this case, the coordinator is simple. T he numPartitions method tells Storm how many partitions there are. A nd be careful not to return any metadata. F or IPartitionedTransactionalSpout, metadata is managed directly by the distributor.
Here's the implementation of the distributor:
01
public static class TweetsPartitionedTransactionalEmitter
02
implements Emitter<TransactionMetadata> {
03
PartitionedRQ rq = new ParttionedRQ();
04
05
@Override
06
public TransactionMetadata emitPartitionBatchNew(TransactionAttempt tx,
07
BatchOutputCollector collector, int partition,
08
TransactionMetadata lastPartitioonMeta) {
09
long nextRead;
10
11
if(lastPartitionMeta == null) {
12
nextRead = rq.getNextRead(partition);
13
}else{
14
nextRead = lastPartitionMeta.from + lastPartitionMeta.quantity;
15
rq.setNextRead(partition, nextRead); //移动游标
16
}
17
18
long quantity = rq.getAvailableToRead(partition, nextRead);
19
quantity = quantity > MAX_TRANSACTION_SIZE ? MAX_TRANSACTION_SIZE : quantity;
20
TransactionMetadata metadata = new TransactionMetadata(nextRead, (int)quantity);
21
22
emitPartitionBatch(tx, collector, partition, metadata);
23
return metadata;
24
}
25
26
@Override
27
public void emitPartitionBatch(TransactionAttempt tx, BatchOutputCollector collector,
28
int partition, TransactionMetadata partitionMeta) {
29
if(partitionMeta.quantity <= 0){
30
return;
31
}
32
33
List<String> messages = rq.getMessages(partition, partitionMeta.from,
34
partitionMeta.quantity);
35
36
long tweetId = partitionMeta.from;
37
for (String msg : messages) {
38
collector.emit(new Values(tx, ""+tweetId, msg));
39
tweetId++;
40
}
41
}
42
43
@Override
44
public void close() {}
45
} Here are two important methods, emitPartitionBatchNew, and emitPartitionBatch. F or emitPartition BatchNew, the partition parameter is received from Storm, which determines which partition the batch should read from. I n this method, decide which tweets to get, generate the appropriate metadata object, call emitPartitionBatch, return the metadata object, and the metadata object is saved to zookeeper as soon as the method returns.
Storm sends the same transaction ID for each partition, indicating that a transaction runs through all data partitions. R ead tweets in the partition and distribute batches to the topology through emitPartitionBatch. If batch processing fails, Storm will call emitPartitionBatch to repeat the batch with saved metadata.
NOTE : Full source code see: https://github.com/storm-book/examples-ch08-transactional-topologies : This is the case, in fact, there is nothing in this warehouse)
A fuzzy transactional topology
So far, you've learned how to have batches with the same transaction ID replayed in the event of an error. B ut in some scenarios this may not be appropriate. And then what happens?
It turns out that you can still implement transactions that are semanticly accurate, but this requires more development work, and you need to document the state before the transactions that are duplicated by Storm. Now that you can get different metagroups for the same transaction ID at different times, you need to reset the transaction to its previous state and continue from there.
For example, if you count all the tweets you receive, you've counted to 5, and the last transaction ID is 321, and you're in the majority of eight. Y ou have to maintain the following three values -- previousCount=5, currentCount=13, and lastTransactionId=321. Assuming that thing ID321 is sent again and you get four more d'ords instead of the previous eight, the commiter detects that this is the same transaction ID, which resets the result to the value 5 of previousCount, adds 4 on that basis, and then updates Count to 9.
In addition, when a previous transaction was canceled, each transaction processed in parallel was canceled. This is to make sure you don't lose any data.
Your spout can implement IOpaquePartitioned TransactionalSpout, and as you can see, the coordinator and distributor are simple.
01
public static class TweetsOpaquePartitionedTransactionalSpoutCoordinator implements IOpaquePartitionedTransactionalSpout.Coordinator {
02
@Override
03
public boolean isReady() {
04
return true;
05
}
06
}
07
08
public static class TweetsOpaquePartitionedTransactionalSpoutEmitter
09
implements IOpaquePartitionedTransactionalSpout.Emitter<TransactionMetadata> {
10
PartitionedRQ rq = new PartitionedRQ();
11
12
@Override
13
public TransactionMetadata emitPartitionBatch(TransactionAttempt tx,
14
BatchOutputCollector collector, int partion,
15
TransactionMetadata lastPartitonMeta) {
16
long nextRead;
17
18
if(lastPartitionMeta == null) {
19
nextRead = rq.getNextRead(partition);
20
}else{
21
nextRead = lastPartitionMeta.from + lastPartitionMeta.quantity;
22
rq.setNextRead(partition, nextRead);//移动游标
23
}
24
25
long quantity = rq.getAvailabletoRead(partition, nextRead);
26
quantity = quantity > MAX_TRANSACTION_SIZE ? MAX_TRANSACTION_SIZE : quantity;
27
TransactionMetadata metadata = new TransactionMetadata(nextRead, (int)quantity);
28
emitMessages(tx, collector, partition, metadata);
29
return metadata;
30
}
31
32
private void emitMessage(TransactionAttempt tx, BatchOutputCollector collector,
33
int partition, TransactionMetadata partitionMeta) {
34
if(partitionMeta.quantity <= 0){return;}
35
36
List<String> messages = rq.getMessages(partition, partitionMeta.from, partitionMeta.quantity);
37
long tweetId = partitionMeta.from;
38
for(String msg : messages) {
39
collector.emit(new Values(tx, ""+tweetId, msg));
40
tweetId++;
41
}
42
}
43
44
@Override
45
public int numPartitions() {
46
return 4;
47
}
48
49
@Override
50
public void close() {}
51
} The most interesting method is emitPartitionBatch, which gets previously submitted metadata. Y ou have to use it to generate batches. T his batch does not need to be consistent with the previous one, and you may not be able to create exactly the same batch at all. The remaining work is done by the submitter bolts with the help of the previous state.