Posts about Zookeeper
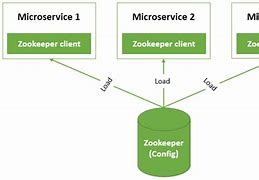
Zookeeper Overview
May 26, 2021 21:00 0 Comment Zookeeper
Distributed applications, Distributed applications, What is Apache ZooKeeper?, The benefits of ZooKeeper, ZooKeeper is a distributed coordination service for managing mainframes., /b10>, Coordinating and managing services in a distributed environment is a

Zookeeper Foundation
May 26, 2021 21:00 0 Comment Zookeeper
ZooKeeper's architecture, ZooKeeper's architecture, Hierarchical namespaces, Sessions (Sessions), Watches (Monitoring), Before diving into how ZooKeeper works, let's take a look at the basic concepts of ZooKeeper., We'll discuss the following topics in this chapter:, 1,
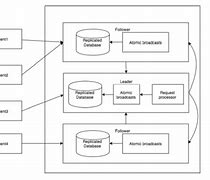
Zookeeper workflow
May 26, 2021 22:00 0 Comment Zookeeper
The nodes in the ZooKeeper cluster, The nodes in the ZooKeeper cluster, Once the ZooKeeper collection starts, it waits for the client to connect., /b10>, The client connects to a node in the ZooKeeper collection., /b11>, I
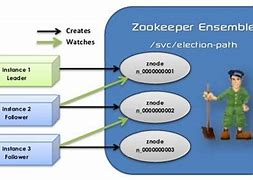
Zookeeper leader election
May 26, 2021 22:00 0 Comment Zookeeper
Zookeeper leader election, Leader elections are key to ensuring distributed data consistency. T, he Leader election is divided into zookeyer cluster initialization start-up elec

Zookeeper installation
May 26, 2021 22:00 0 Comment Zookeeper
Step 1: Verify the Java installation, Step 1: Verify the Java installation, Step 2: ZooKeeper frame installation, Before installing ZooKeeper, make sure that your system is running on any of the following operating systems:, Any Linux OS, - Supports development an
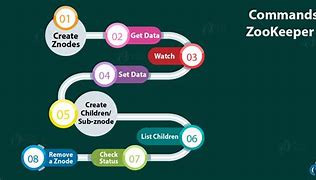
Zookeeper CLI
May 26, 2021 22:00 0 Comment Zookeeper
Create Znodes, Create Znodes, Get the data, Watch (Monitoring), Set up the data, Create a child/child node, Children are listed, Check the status, Remove Znode, The ZooKeeper Command Line Interface (CLI) is used to interact with the ZooKeeper collection for development., It helps debug and resolve different op
Zookeeper API
May 26, 2021 22:00 0 Comment Zookeeper
The basics of the ZooKeeper API, The basics of the ZooKeeper API, Java binding, Connect to the ZooKeeper collection, Create Znode, Exists - Check the presence of Znode, GetData method, SetData method, GetChildren method, Delete Znode, ZooKeeper has an official API that binds Java and C. T, he Zookeeper community provides unofficial APIs for most languages (.NET, python, etc.)., /b10

Zookeeper app
May 26, 2021 22:00 0 Comment Zookeeper
Yahoo, Yahoo, Apache Hadoop, Apache HBase, Apache Solr, Zookeeper provides a flexible, coordinated infrastructure for distributed environments., /b10>, The ZooKeeper framework supports many of today's best

Which is best apache storm or apache zookeeper?
Nov 29, 2021 10:00 0 Comment Zookeeper
It is a streaming data framework that has the capability of highest ingestion rates. Though Storm is stateless, it manages distributed environment and cluster state via Apache ZooKeeper. It is simple and you can execute all kinds of manipulations on real-time data in parallel. Apache Storm is contin