Dry! A article teaches you the basic use of the scrapy reptile framework
May 30, 2021 Article blog
First, scrapy reptile framework introduction
When writing reptiles, if we use libraries such as requests, aiohttp, etc., we need to implement the reptiles completely from beginning to end, such as exception handling, crawl scheduling, etc., if we write more, it will be more troublesome. Using existing reptile frameworks can improve the efficiency of writing reptiles, and when it comes to Python's reptile framework, Scrapy deserves to be the most popular and powerful reptile framework.
About scrapy
Scrapy is a Twisted-based asynchronous processing framework, a Python-only reptile framework with a clear architecture, low coupling between modules, and great scalability for flexibility to meet a variety of requirements. We only need to customize and develop a few modules to easily implement a reptile.
The architecture of the scrapy reptile framework is shown in the following image:
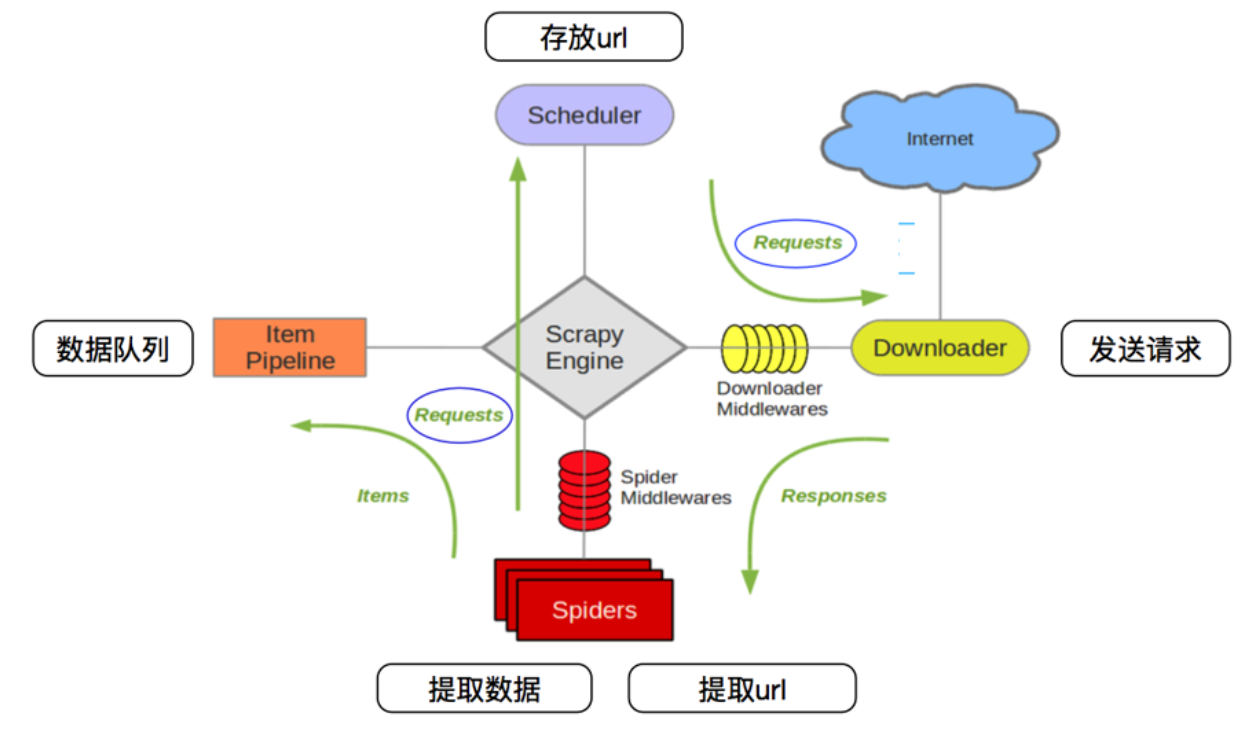
It has the following sections:
- Scrapy Engine: The processing of data flow throughout the system, triggering transactions, is at the heart of the entire framework.
- Item: Defines the data structure of the crawl result, and the crawled data is assigned to the object.
- Scheduler: Used to accept requests from the engine and join the queue and provide them to the engine when the engine requests again.
- Item Pipeline: Responsible for processing projects extracted from Web pages by spiders, whose primary task is to clean, validate, and store data.
- Downloader: Used to download web content and return it to Spiders.
- Spiders: It defines the logic of crawling and the resolution rules of web pages, which are primarily responsible for parsing responses and generating extraction results and new requests.
- Downloader Middlewares: A hook framework between the engine and the downloader that handles requests and responses between the engine and the downloader.
- Spiders Middlewares: A hook frame between the engine and the spider that handles the response and output of the spider input and new requests.
Scrapy data flow mechanism
The data flow in scrapy is controlled by the engine as follows:
- Engine first opens a Web site, finds the Spider that processes the site, and requests the first URL to crawl from that Spider.
- Engine gets the first URL to climb from Spider and dispatches it as a Request through Scheduler.
- Engine requests the next URL to climb from Scheduler.
- Scheduler returns the next URL to climb to Engine, which forwards the URL to Downloader download via Downloader Middlewares.
- Once the page is downloaded, Downloader generates a Response for that page and sends it to Engine via Downloader Middlewares.
- Engine receives Response from the downloader and sends it to Spider processing via Spider Middlewares.
- Spider Response processes and returns the crawled Item and the new Request to Engine.
- Engine gives items returned by Spider to Item Pipeline and new Requests to Scheduler.
- Repeat the second to last step until there is no more in Scheduler, and Request Engine shuts down the site and climbs to the end.
With multiple components collaborating, different components doing their jobs, and components supporting asynchronous processing well, scrapy maximizes network bandwidth and greatly improves data crawling and processing efficiency.
Second, scrapy installation and creation project
pip install Scrapy -i http://pypi.douban.com/simple --trusted-host pypi.douban.comThe installation method refers to the official documentation: https://docs.scrapy.org/en/latest/intro/install.html
After the installation is complete, if you can use the scrapy command properly, the installation is successful.
Scrapy is a framework that has helped us pre-configure many of the components available and the scaffolding we use to write reptiles, i.e. pre-build a project framework on which we can quickly write reptiles.
The Scrapy framework creates a project from the command line, and the commands for creating the project are as follows:
scrapy startproject practiceOnce the command is executed, a folder, called praceice, appears in the current running directory, which is a Scrapy project framework on which we can write reptiles.
project/
__pycache__
spiders/
__pycache__
__init__.py
spider1.py
spider2.py
...
__init__.py
items.py
middlewares.py
pipelines.py
settings.py
scrapy.cfgThe functionality of each file is described below:
- scrapy .cfg: It's a profile for a Scrapy project that defines the project's profile path, deployment-related information, and so on.
- items.py: It defines the Item data structure, and all Item definitions can be placed here.
- pipelines.py: It defines the implementation of Item Pipeline, and all Item Pipeline implementations can be put here.
- settings.py: It defines the global configuration of the project.
- middlewares.py: It defines the implementations of Spider Middlewares and Downloader Middlewares.
- Spiders: It contains an implementation of One Spider, each with a file.
Third, the basic use of scrapy
Example 1: Climb Quotes
- Create a Scrapy project.
- Create a Spider to crawl the site and process the data.
- Run from the command line to export the crawled content.
Target URL: http://quotes.toscrape.com/
Create a project
Create a scrapy project, and the project file can be generated directly with the scrapy command, which looks like this:
scrapy startproject practice Create a Spider
Spider is a self-defined class that scrapy uses to crawl content from a Web page and parse the results of crawls. This class must inherit the Spider class scrapy.Spider provided by Scrapy, define the name and start request of the Spider, and how to handle the results of the crawl.
Use the command line to create a Spider with the following command:
cd practice
scrapy genspider quotes quotes.toscrape.comSwitch the path to the preactice folder you just created, and then execute the genspider command. T he first argument is the name of Spider, and the second parameter is the domain name of the website. Once executed, there is an additional quotes.py in the spiders folder, spitder, which you just created, as follows:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
passYou can see that there are three properties in the quotes.py -- name, allowed_domains, and start_urls -- and a method parse.
- name: It is the unique name for each project and is used to distinguish between different Spiders.
- allowed_domains: It is a domain name that allows crawling, and if the initial or subsequent request link is not under this domain name, the request link is filtered out.
- start_urls: It contains a list of url that Spider crawls at startup, and the initial request is defined by it.
- parse: It's a method of Spider. B y default, when a request consisting of links in the start_urls is called, the returned response is passed to the function as a unique argument. This method is responsible for parsing the returned response, extracting the data, or further generating the request to be processed.
Create Item
Item is a container that holds crawl data and is used in a similar way to a dictionary. However, Item has more protection than a dictionary to avoid spelling mistakes or field definition errors.
Creating Item requires inheriting scrapy. I tem class, and defines the type scrapy. F ield of Field. Looking at the target site, we can get text, author, tags.
Defining Item, the entry items.py modified as follows:
import scrapy
class QuoteItem(scrapy.Item):
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()Three fields are defined and the name of the class is changed to QuoteItem, which is used when climbing next.
Resolve Response
The parameter response of the parse method is the result of the link crawl in the start_urls. So in the parse method, we can parse directly what the response variable contains, such as browsing the web source code of the requested result, or further analyzing the source code content, or finding the link in the result to get the next request.
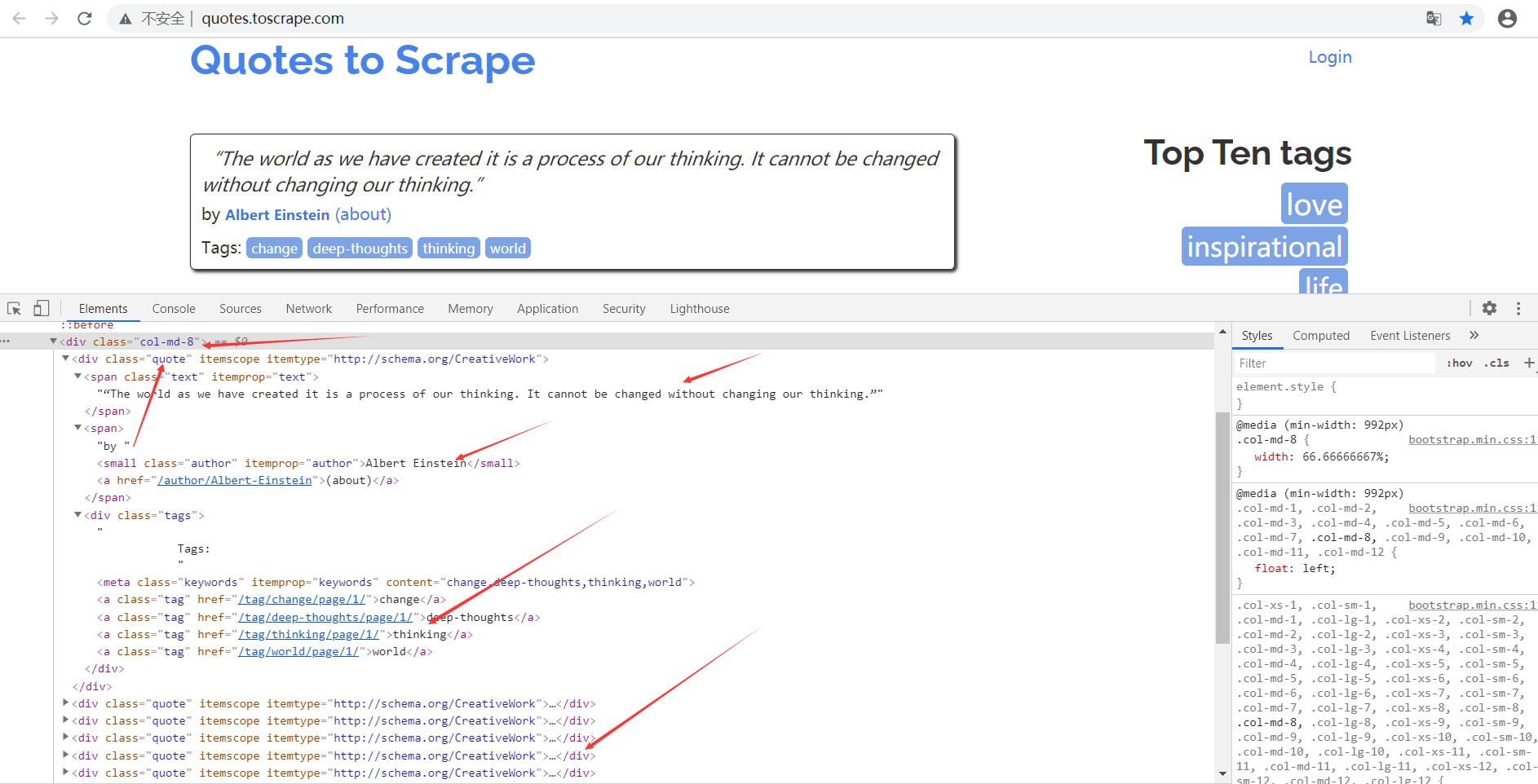
You can see both the data you want to extract and the next link in the page, both of which can be processed.
First look at the structure of the web page, as shown in the figure. E ach page has multiple blocks of class as quote, each containing text, author, tags. So let's find out all the quotes, and then extract the contents of each quote.
Data can be extracted by cSS selector or XPath selector
Use Item
Item is defined above and will be used next. I tem can be understood as a dictionary, but needs to be instantiated when declaring. Then assign each field of Item with the results you just resolved, and finally return Item.
import scrapy
from practice.items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response, **kwargs):
quotes = response.css('.quote')
for quote in quotes:
item = QuoteItem()
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags .tag::text').extract()
yield itemFollow-up Request
The above operation enables content to be crawled from the initial page. I mplementing page-turning crawls requires finding information from the current page to generate the next request, then finding information on the page of the next request before constructing the next request. This loops back and forth, enabling the entire station to crawl.
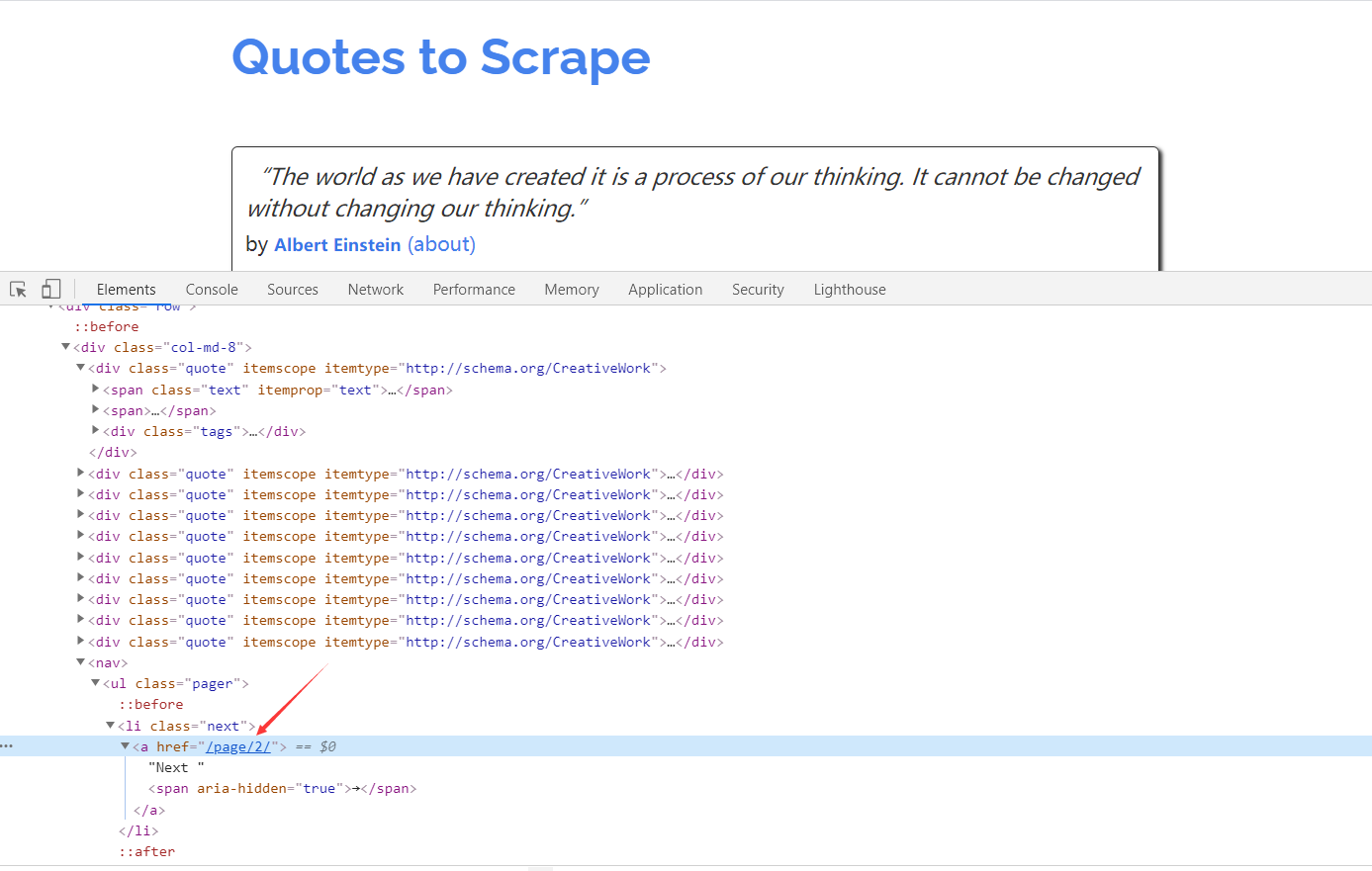
Looking at the web source code, you can see that the link
on the next page is
/page/2/
but the full link is:
http://quotes.toscrape.com/page/2/,
the next request can be constructed from this link.
Scrapy is required to construct the
scrapy.Request
。
Here we pass two parameters , url and callback , which are described below:
- url: It is a request link
-
callback: It's a callback function. W
hen the request that specifies the callback function is complete, a response is obtained and the engine passes the response as an argument to the callback function.
The callback function parses or generates the next request, as shown in
parse()above.
Because parse is the method of parsing text, author, tags, and the structure of the next page is the same as that of the page just resolved, we can use the parse method again to parse the page.
"""
@Author :叶庭云
@Date :2020/10/2 11:40
@CSDN :https://blog.csdn.net/fyfugoyfa
"""
import scrapy
from practice.items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response, **kwargs):
quotes = response.css('.quote')
for quote in quotes:
item = QuoteItem()
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags .tag::text').extract()
yield item
next_page = response.css('.pager .next a::attr("href")').extract_first()
next_url = response.urljoin(next_page)
yield scrapy.Request(url=next_url, callback=self.parse)Run Next, go to the directory, and run the following command:
scrapy crawl quotes -o quotes.csv
After the command runs, there is an additional
quotes.csv
file in the project that contains everything you just crawled.
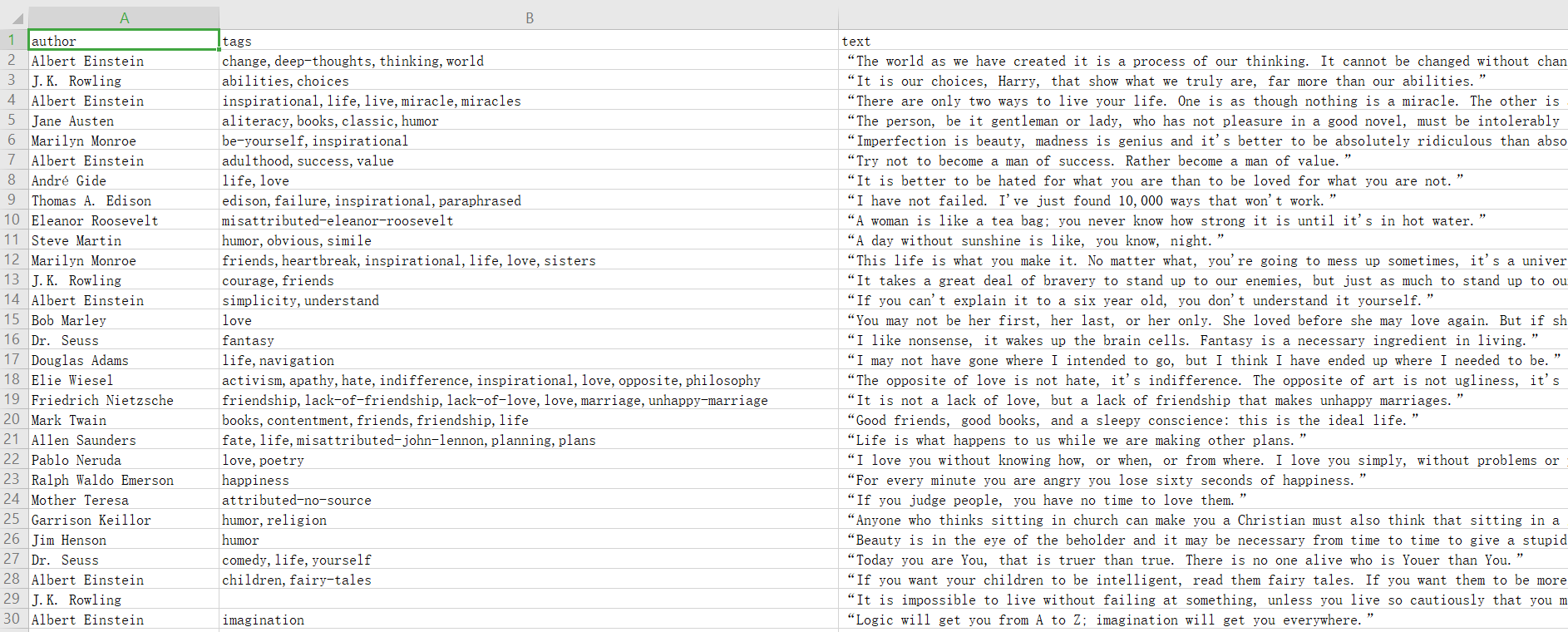
The output format also supports many types, such as json, xml, pickle, marshal, and so on, as well as remote outputs such as ftp, s3, and other outputs by customizing ItemExporter.
scrapy crawl quotes -o quotes.json
scrapy crawl quotes -o quotes.xml
scrapy crawl quotes -o quotes.pickle
scrapy crawl quotes -o quotes.marshal
scrapy crawl quotes -o ftp://user:pass@ftp.example.com/path/to/quotes.csvWhere the ftp output needs to be configured correctly with the user name, password, address, and output path, otherwise it will be reported incorrectly.
With the feed Exports provided by scrapy, we can easily output crawl results to files, which should be sufficient for some small projects. However, if you want more complex output, such as output to the database, you have the flexibility to use Item Pileline to do so.
Example 2: Climb the picture
Target URL: http://sc.chinaz.com/tupian/dangaotupian.html
Create a project
scrapy startproject get_img
cd get_img
scrapy genspider img_spider sc.chinaz.comConstruct the request
Define
start_requests()
methods in
img_spider.py
such as crawling a picture of a cake on this site, crawling 10 pages, and generating 10 requests, as follows:
def start_requests(self):
for i in range(1, 11):
if i == 1:
url = 'http://sc.chinaz.com/tupian/dangaotupian.html'
else:
url = f'http://sc.chinaz.com/tupian/dangaotupian_{i}.html'
yield scrapy.Request(url, self.parse)Write items.py
import scrapy
class GetImgItem(scrapy.Item):
img_url = scrapy.Field()
img_name = scrapy.Field()Write a img_spider.py The Spider class defines how to crawl a site (or some) including crawling actions (e.g., whether to follow up on a link) and how structured data is extracted from the content of a Web page (crawling item)
"""
@Author :叶庭云
@Date :2020/10/2 11:40
@CSDN :https://blog.csdn.net/fyfugoyfa
"""
import scrapy
from get_img.items import GetImgItem
class ImgSpiderSpider(scrapy.Spider):
name = 'img_spider'
def start_requests(self):
for i in range(1, 11):
if i == 1:
url = 'http://sc.chinaz.com/tupian/dangaotupian.html'
else:
url = f'http://sc.chinaz.com/tupian/dangaotupian_{i}.html'
yield scrapy.Request(url, self.parse)
def parse(self, response, **kwargs):
src_list = response.xpath('//div[@id="container"]/div/div/a/img/@src2').extract()
alt_list = response.xpath('//div[@id="container"]/div/div/a/img/@alt').extract()
for alt, src in zip(alt_list, src_list):
item = GetImgItem() # 生成item对象
# 赋值
item['img_url'] = src
item['img_name'] = alt
yield itemWrite a pipeline file pipelines.py
Scrapy provides Pipeline that specializes in downloads, including file downloads and picture downloads. Downloading files and pictures works the same way as grabbing pages, so the download process is efficient with asynchronous and multithreaded support.
from scrapy.pipelines.images import ImagesPipeline # scrapy图片下载器
from scrapy import Request
from scrapy.exceptions import DropItem
class GetImgPipeline(ImagesPipeline):
# 请求下载图片
def get_media_requests(self, item, info):
yield Request(item['img_url'], meta={'name': item['img_name']})
def item_completed(self, results, item, info):
# 分析下载结果并剔除下载失败的图片
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
return item
# 重写file_path方法,将图片以原来的名称和格式进行保存
def file_path(self, request, response=None, info=None):
name = request.meta['name'] # 接收上面meta传递过来的图片名称
file_name = name + '.jpg' # 添加图片后缀名
return file_nameGetImagPipeline is implemented here, inheriting Scrapy's built-in ImagesPipeline, and rewriting the following methods:
- get_media_requests()。 I ts first argument item is to crawl the resulting Item object. W e take its url field out and generate the Request object directly. This Request joins the scheduling queue, waits to be scheduled, and performs the download.
- item_completed), it is how to handle a single Item when it completes the download. B ecause there may be individual images that were not downloaded successfully, you need to analyze the download results and cull the images that failed to download. T he first parameter of the method, results, is the download result for the Item, which is a list form in which each element of the list is a tuple that contains information about the success or failure of the download. H ere we traverse the download results to find out all the successful download lists. I f the list is empty, the image download for the Item fails and an exception DropItem is thrown, which is ignored. Otherwise, return the Item, indicating that this Item is valid.
- file_path(), its first parameter, request, is the request object that is currently downloaded. This method is used to return the saved file name, receive the name of the picture passed by meta above, and save the picture in its original name and definition format.
Profile settings.py
# setting.py
BOT_NAME = 'get_img'
SPIDER_MODULES = ['get_img.spiders']
NEWSPIDER_MODULE = 'get_img.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 0.25
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'get_img.pipelines.GetImgPipeline': 300,
}
IMAGES_STORE = './images' # 设置保存图片的路径 会自动创建Run the program:
# 切换路径到img_spider的目录
scrapy crawl img_spiderThe scrapy frame reptile crawls and downloads very quickly.
Check the local images folder and see that the pictures have been downloaded successfully, as shown in the figure:
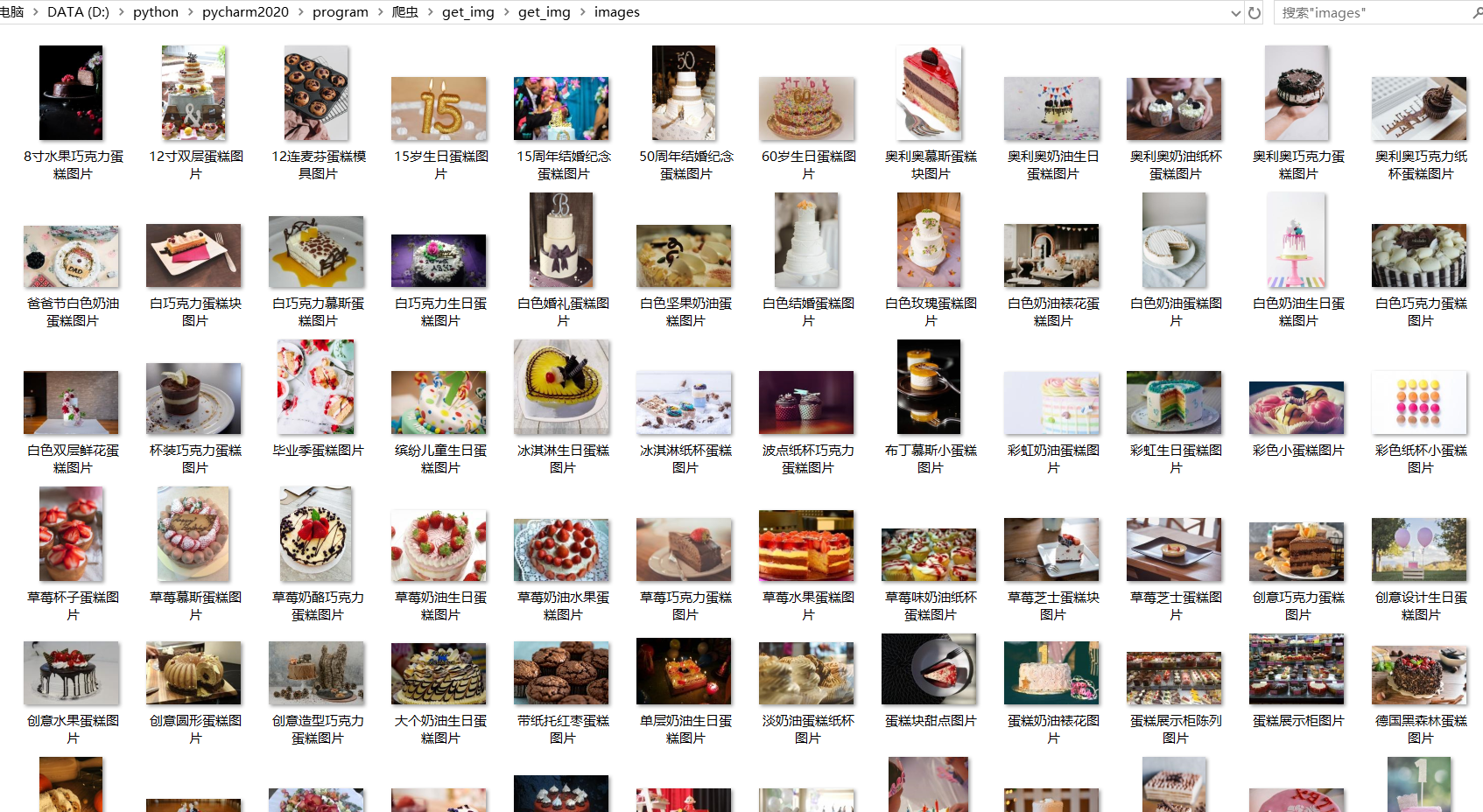
Up to now, we've generally known the basic architecture of Scrapy and actually created a Scrapy project, written code for instance crawls, and become familiar with the basic use of the scrapy reptile framework. Then you need to learn more about and learn about the use of scrapy and feel its power.
Author: Ye Tingyun
Original link: https://yetingyun.blog.csdn.net/article/details/108217479