Storm Spouts
May 17, 2021 Storm getting Started
Table of contents
Spouts
You'll learn in this chapter about spout as the most common design strategy associated with topological entry and its fault tolerance mechanism.
Reliable Message VS Unreliable News
When designing a topology, one important thing that is always in mind is the reliability of the message. W hen there are messages that cannot be processed, you decide what to do and what to do as a topology as a whole. F or example, when dealing with bank deposits, it is important not to lose any transaction messages. But if you want to statistically analyze millions of tweets, even if one is missing, you can still think your results are accurate.
For Storm, it is the developer's responsibility to guarantee the reliability of messages based on the needs of each topology. T his involves a trade-off between message reliability and resource consumption. A high-reliability topology must manage lost messages and inevitably consume more resources; Regardless of the reliability strategy chosen, Storm offers different tools to implement it.
To manage reliability in spout, you can include a tuple ID (new Values (...), tupleId) when distributing. T he ack method is called when a metagroup is handled correctly, and the fail method is called when it fails. When a tugroup is processed by all target bolts and anchor bolts, the tugroup processing is determined to be successful (you'll learn more about anchor bolts in Chapter 5).
The meta-processing fails when one of the following occurs:
- The spout that provides the data calls collector.fail (tuple).
- The processing time exceeds the configured timeout
Let's look at an example. Imagine you're dealing with banking, and the requirements are as follows:
- If the transaction fails, resend the message
- If too many failures are failed, the topology run is terminated
Create a spout and a bolt, spout randomly send 100 transaction IDs, and 80% of tuppies will not be received by bolt (you can view the full code in example ch04-spout). The map is used to distribute transactional message metagroups when spout is implemented, which makes it easier to reseed messages.
public void nextTuple() {
if(!toSend.isEmpty()){
for(Map.Entry<Integer, String> transactionEntry : toSend.entrySet()){
Integer transactionId = transactionEntry.getKey();
String transactionMessage = transactionEntry.getValue();
collector.emit(new Values(transactionMessage),transactionId);
}
toSend.clear();
}
} If there are unsended messages, get each transaction message and its associated ID, send them out as a metagroup, and finally empty the message queue. It is worth noting that it is safe to call the clear of the map because when nextTuple fails, only the ack method modifies the map, and they all run within a thread.
Maintenance of two maps is used to track transaction messages to be sent and the number of failures per transaction. The ack method simply removes the transaction from each list.
public void ack(Object msgId) {
messages.remove(msgId);
failCounterMessages.remove(msgId);
} The fail method determines whether a message should be resend or abandoned after it has failed too many times.
NOTE: If you use all the data flow groups and all the bolts in the topology fail, spout's fail method is called.
public void fail(Object msgId) {
Integer transactionId = (Integer) msgId;
//检查事务失败次数
Integer failures = transactionFailureCount.get(transactionId) + 1;
if(failes >= MAX_FAILS){
//失败数太高了,终止拓扑
throw new RuntimeException("错误, transaction id 【"+
transactionId+"】 已失败太多次了 【"+failures+"】");
}
//失败次数没有达到最大数,保存这个数字并重发此消息
transactionFailureCount.put(transactionId, failures);
toSend.put(transactionId, messages.get(transactionId));
LOG.info("重发消息【"+msgId+"】");
} First, check the number of transaction failures. I f a transaction fails too many times, terminate the worker who sent this message by throwing RuntimeException. O therwise, the number of failed saves and putting the message in the queue to be sent (toSend) allows it to be resend when nextTuple is called again.
NOTE: Storm nodes do not maintain state, so if you save information in memory (as in this case), and the node is unfortunately hung up, you will lose all cached messages. S torm is a system that fails quickly. The topology hangs up when an exception is thrown, and then restarts by Storm to the state it was in before the exception was thrown.
Get the data
Next you'll learn some tips for designing spouts to help you get data from multiple data sources.
Connect directly
In a directly connected schema, spout is directly connected to a message distributor.
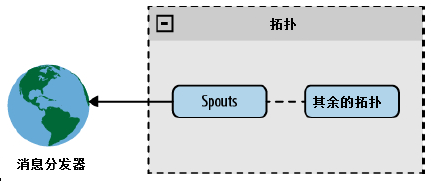
Figure Directly connected spout
This architecture is easy to implement, especially if the message distributor is a known device or a known device group. K nown device satisfaction: The topology knows the device from startup and remains the same throughout the life cycle of the topology. U nknown devices are added during the topology run. A known device group is known to all devices in the group when it starts from the topology.
Here's an example of that. C reate a spout that uses the Twitter Stream API to read the twitter stream. S pout connects the API directly as a message distributor. G et a public tweet from the data stream that conforms to the track parameter (refer to the twitter development page). Complete examples can be found https://github.com/storm-book/examples-ch04-spouts/ link.
Spout gets the connection parameters (track, user, password) from the configuration object and connects to the API (in this case, DefaultHttpClient of Apache). It reads a row of data at a time, converts the data from JSON to a Java object, and then publishes it.
public void nextTuple() {
//创建http客户端
client = new DefaultHttpClient();
client.setCredentialsProvider(credentialProvider);
HttpGet get = new HttpGet(STREAMING_API_URL+track);
HttpResponse response;
try {
//执行http访问
response = client.execute(get);
StatusLine status = response.getStatusLine();
if(status.getStatusCode() == 200){
InputStream inputStream = response.getEntity().getContent();
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
String in;
//逐行读取数据
while((in = reader.readLine())!=null){
try{
//转化并发布消息
Object json = jsonParser.parse(in);
collector.emit(new Values(track,json));
}catch (ParseException e) {
LOG.error("Error parsing message from twitter",e);
}
}
}
} catch (IOException e) {
LOG.error("Error in communication with twitter api ["+get.getURI().toString()+"],
sleeping 10s");
try {
Thread.sleep(10000);
} catch (InterruptedException e1) {}
}
} NOTE: Here you lock the nextTuple method, so you'll never execute the ack and fail methods. In a real-world application, we recommend that you perform a lock in a separate thread and maintain an internal queue to exchange data (you'll learn how to do this in the next example: message queues).
That's great! N ow you read Twitter data with a spout. I t is wise to use topology parallelization, where multiple spouts read different parts of the data from the same stream. S o what do you do if you have multiple streams to read? S torm's second interesting feature, which has already appeared, is the same as the original text, but according to Chinese's wording habits or not to reuse the wording, you can access TopOlogyText within any component. With this feature, you can divide the stream into multiple spouts to read.
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
//从context对象获取spout大小
int spoutsSize =
context.getComponentTasks(context.getThisComponentId()).size();
//从这个spout得到任务id
int myIdx = context.getThisTaskIndex();
String[] tracks = ((String) conf.get("track")).split(",");
StringBuffer tracksBuffer = new StringBuffer();
for(int i=0; i< tracks.length;i++){
//Check if this spout must read the track word
if( i % spoutsSize == myIdx){
tracksBuffer.append(",");
tracksBuffer.append(tracks[i]);
}
}
if(tracksBuffer.length() == 0) {
throw new RuntimeException("没有为spout得到track配置" +
" [spouts大小:"+spoutsSize+", tracks:"+tracks.length+"] tracks的数量必须高于spout的数量");
this.track =tracksBuffer.substring(1).toString();
}
...
} With this technique, you can distribute collector objects evenly across multiple data sources, and of course you can apply them to other situations. For example, collect log files from a web server
Figure Straight to hash
From the previous example, you learned to connect from a spout to a known device. Y ou can also use the same method to connect unknown devices, but at this point you need to rely on a list of devices that are maintained in collaboration with the system. T he collaborative system is responsible for detecting changes in the list and creating or destroying connections based on the changes. F or example, when collecting log files from a web server, the list of web servers may change over time. When you add a web server, the collaborative system explores the change and creates a new spout for it.
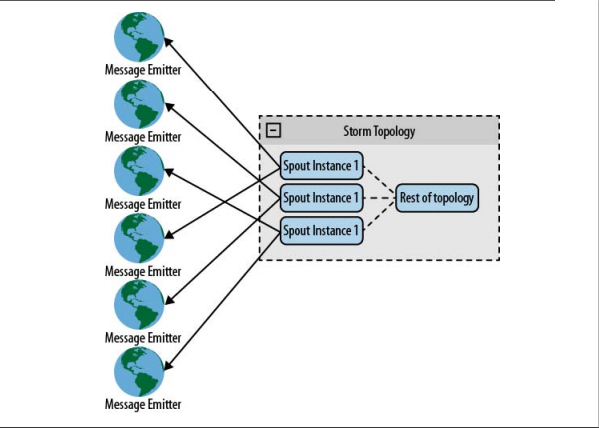
Figure Direct collaboration
The message queue
The second approach is to receive messages from the message distributor through a queue system and forward the messages to spout. A step further, using the queue system as a middleware between spout and the data source, in many cases you can take advantage of the replay capabilities of the multi-queue system to enhance queue reliability. T his means that you don't need to know anything about the message distributor, and adding or removing the distributor is much simpler than connecting directly. The problem with this architecture is that queues are a point of failure, and you have to introduce new aspects to the process.
The following illustration shows this architectural model
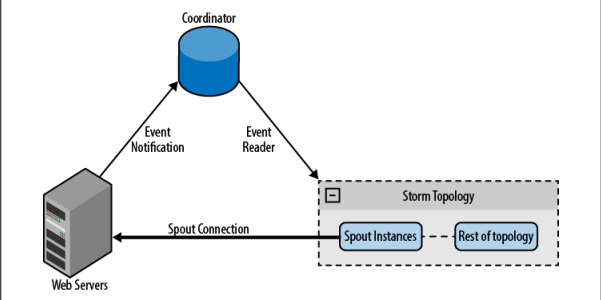
Figure Using the queue system
NOTE: You can parallel between multiple spouts by polling queues or hash queues (sending queue messages to spouts via hashing or creating multiple queues to make queue spouts one-to-one correspondence).
Next we create a http://redis.io/ using redis and its java library Jedis. I n this example, we create a log processor that collects logs from an unknown source, uses the lpush command to insert messages into the queue, and waits for messages with the blpop command. If you have a lot of processing, the blpop command uses polling to get the message.
We create a thread in the open method of spout to get the message (using the thread to avoid locking nextTuple's call in the main loop):
new Thread(new Runnable() {
@Override
public void run() {
try{
Jedis client= new Jedis(redisHost, redisPort);
List res = client.blpop(Integer.MAX_VALUE, queues);
messages.offer(res.get(1));
}catch(Exception e){
LOG.error("从redis读取队列出错",e);
try {
Thread.sleep(100);
}catch(InterruptedException e1){}
}
}
}).start(); The sole purpose of this thread is to create a redis connection and then execute the blpop command. W henever a message is received, it is added to an internal message queue and then consumed by NextTuple. For spout, the data source is the redis queue, which does not know where the message distributor is or the number of messages.
NOTE: We do not recommend that you create too many threads in spout because each spout runs on a different thread. A better alternative would be to increase topological parallelity by creating more threads in a distributed environment through Storm clusters.
In the nextTupl e method, the only thing to do is to get messages from the internal message queue and distribute them again.
public void nextTuple(){
while(!messages.isEmpty()){
collector.emit(new Values(messages.poll()));
}
} NOTE: You can also achieve a reliable topology by replaying messages at spout with redis. (Here is a reliable message vs unreliable message relative to the beginning)
DRPC
DRPCSpout receives a function call from the DRPC server and executes it (see example in Chapter 3). For the most common cases, it is sufficient to use backtype.storm.drpc.DRPCSpout, but it is still possible to create your own implementation using the DRPC class within the Storm package.
Summary
Now you've learned about common spout implementation patterns, their benefits, and how to ensure message reliability. T here is no schema pattern for all topology. I f you know the data sources and can control them, you can use direct connections, but if you need to add unknown data sources or receive data from multiple data sources, it's best to use message queues. If you want to perform an online process, you can use DRPCSpout or something like that.
You've learned three common ways to connect, but there are still endless possibilities depending on your needs.