Apache Kafka Foundation
May 26, 2021 Apache Kafka
For big data, we have a lot of questions to consider, first how to collect large amounts of data (such as Flume), then how to store the collected data (typical distributed file system HDFS, distributed database HBase, NoSQL database Redis), and second, the stored data is not saved, to get useful information through calculations, which involves computing models (typical offline computing MapReduce, streaming real-time computing Storm, S park) or to mine information from the data, machine learning algorithms are required. O n top of this, there are a variety of tools for querying and analyzing data (e.g. Hive, Pig, etc.). In addition, building distributed applications requires tools such as Zookeeper, a distributed coordination service.
Here, we're talking about messaging systems, Kafka is designed for distributed high throughput systems, and Kafka has better throughput, built-in partitioning, replication, and inherent fault tolerance than other messaging systems, making it ideal for large-scale messaging applications.
(i) The messaging system
First, let's look at what a messaging system is: a messaging system is responsible for transferring data from one application to another, allowing the application to focus on processing logic without having to think too much about how to share messages.
Distributed messaging systems are based on a reliable way of queuing messages, which are queued asynchronously between the application and the messaging system. In fact, messaging systems have two messaging patterns: one is point-to-point and the other is a publish-subscribe-based messaging system.
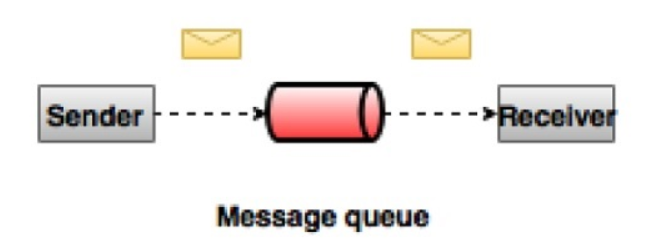
1, point-to-point messaging system
In a point-to-point messaging system, messages remain in a queue, and one or more consumers can consume messages in the queue, but messages can only be consumed by up to one consumer, and once a consumer consumes them, the message disappears from the queue. N ote here: Multiple consumers can work at the same time, but only one of them will eventually get the message. The most typical example is an order processing system where multiple order processors can work at the same time, but for a particular order, only one of the order processors can take the order for processing.
2, publish-subscribe to the messaging system
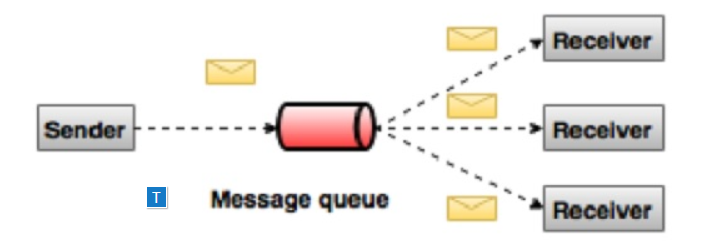
In the publish-subscribe system, messages are retained in the topic. U nlike a point-to-point system, consumers can subscribe to one or more topics and use all messages in that topic. I n a publish-subscribe system, a message producer is called a publisher and a message consumer is called a subscriber. A real-life example is Dish TV, which publishes different channels such as sports, movies, music, etc., and anyone can subscribe to their own channel set and get their subscription to the channel when available.
(ii) Introduction to Apache Kafka
Kafka is a distributed,partitioned,replicated commit logservice。
Apache Kafka is a distributed publishing-subscription messaging system and a powerful queue that can process large amounts of data and enable you to deliver messages from one endpoint to another. K afka is suitable for offline and online messaging. K afka messages remain on disk and are replicated within the cluster to prevent data loss. K afka is built on zooKeeper synchronization services. It integrates well with Apache Storm and Spark for real-time streaming data analysis.
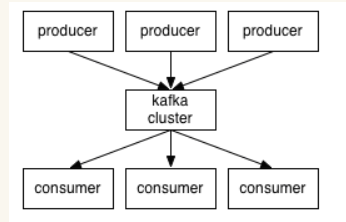
Kafka is a distributed message queue with high performance, persistence, multi-replica backup, and scale-out capabilities. P roducers write messages into the queue, and consumers take messages from the queue for business logic. Generally in the architectural design to play the role of decoupling, peak cutting, asynchronous processing.
Key terms:
(1) Producer and consumer (producer and consumer): The sender of the message is producer, the consumer and recipient of the message is Consumer, the producer saves the data to the Kafka cluster from which the consumer obtains the message for business processing.
(2) Broker: There are many Servers in the Kafka cluster, each of which can store messages, calling each Server a kafka instance, also known as a broker.
(3) Topic: A topic holds the same type of message, equivalent to a classification of the message, and each producer sends the message to kafka, indicating which topic to save, that is, which class the message belongs to.
(4) Partition: Each topic can be divided into partitions, each partition is an append log file at the storage level. A ny messages published to this partition are appended directly to the end of the log file. W hy partition? The most fundamental reason is: kafka file-based storage, when the content of the file to a certain extent, it is easy to reach the upper limit of a single disk, therefore, the use of partitioning, a partition corresponding to a file, so that the data can be stored separately on different servers, in addition to this can also be load balanced to accommodate more consumers.
(5) Offset: A partition corresponds to a file on a disk, and the position of the message in the file is called offset, and offset is a long number that can uniquely mark a message. Because kafka does not provide additional indexing mechanisms to store offset, files can only be read and written sequentially, so "random reading and writing" of messages is almost not allowed in kafka.
To sum up, let's summarize a few key points of Kafka:
- kafka is a distributed message system based on publish-subscribe (message queue)
- Kafka is for big data, messages are saved in topics, and each topic is divided into multiple partitions
- Kafak's message data is stored on disk, and each partition corresponds to a file on the disk, and message writing is a simple file append that can be copied within the cluster to prevent loss
- Even if the message is consumed, kafka does not delete the message immediately and can be configured so that it is automatically deleted after a period of time to free up disk space
- Kafka relies on Zookeeper, a distributed coordination service, for offline/online information consumption, often in combination with real-time streaming data analysis such as storm and saprk
(iii) Apache Kafka Fundamentals
Through previous introductions, we have a simple understanding of kafka, which was designed to create a unified information collection platform that enables real-time feedback on information. K afka is a distributed,partitioned,replicated commit logservice。 Next, we focus on several aspects of the analysis of its basic principles.
1. Distributed and partitioned (distributed, partitioned)
We say kafka is a distributed messaging system, called distributed, and we've actually got a rough idea of that. M essages are stored in Topic, and in order to be able to store big data, a topic is divided into partitions, one for each file, which can be stored separately on different machines for distributed cluster storage. In addition, each partition can have a certain number of copies backed up to multiple machines to improve availability.
In summary, multiple partitions corresponding to a topic are distributed to multiple brokers in the cluster, stored as a partition for a file, each of which is responsible for the reading and writing of messages stored in the partition on his own machine.
2, copy (replicated)
Kafka can also configure the number of replicas that partitions need to back up, each of which will be backed up to multiple machines to improve availability, and the number of backups can be specified through a profile.
This redundant backup approach is common in distributed systems, so having a copy involves how multiple backups of the same file are managed and scheduled. K afka's approach is that each partition elects a server as "leader" and the leader is responsible for all reads and writes to the partition, while the other servers, as followers, simply synchronize with the leader and keep following up. If the original leader fails, the new leader will be re-elected by another follower.
As for how to choose a leader, if we actually know ZooKeeper, that's exactly what Zookeeper is good at, and Kafka uses ZK to select a Controller in Broker for partition allocation and Leader elections.
In addition, here we can see that the server that is actually the leader takes on all the read and write requests for the partition, so the pressure is relatively large, and overall, how many partitions means how many leader there will be, kafka will spread the leader over different brokers to ensure overall load balancing.
3, the overall data flow
Kafka's overall data stream meets the following diagram, which can be said to summarize the fundamentals of the entire kafka.
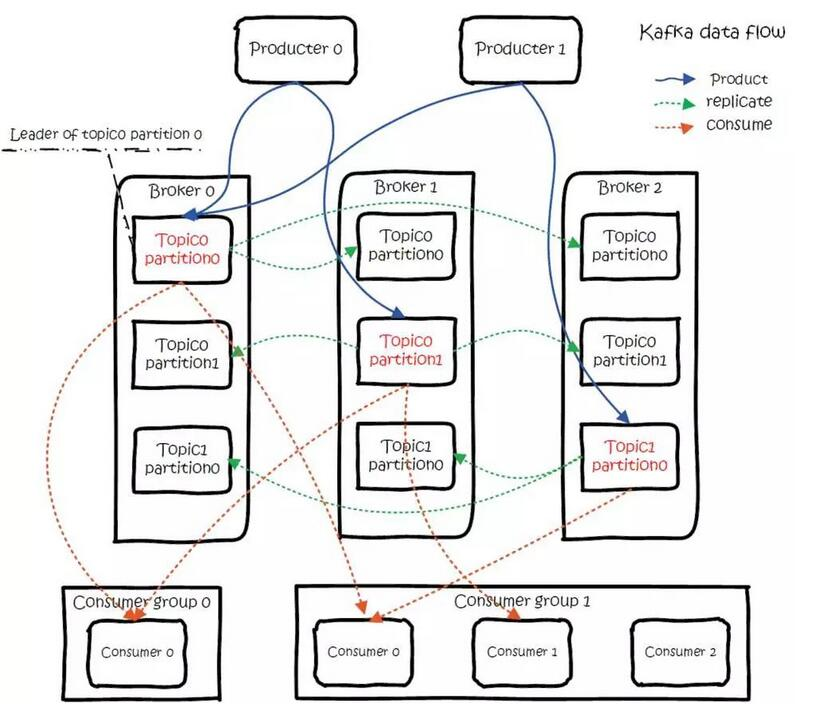
(1) Data Production Process (Produce)
For a record to be written by a producer, you can specify four parameters: topic, partition, key, and value, where topic and value (the data to be written) must be specified, and key and partition are optional.
For a record, serialize it and then follow Topic and Partition into the corresponding send queue. I f Partition doesn't fill in, the situation will be like this: a, Key has filled in. F ollow Key for a hash, and the same Key goes for a Partition. b , Key didn't fill it in. Round-Robin picks Partition.
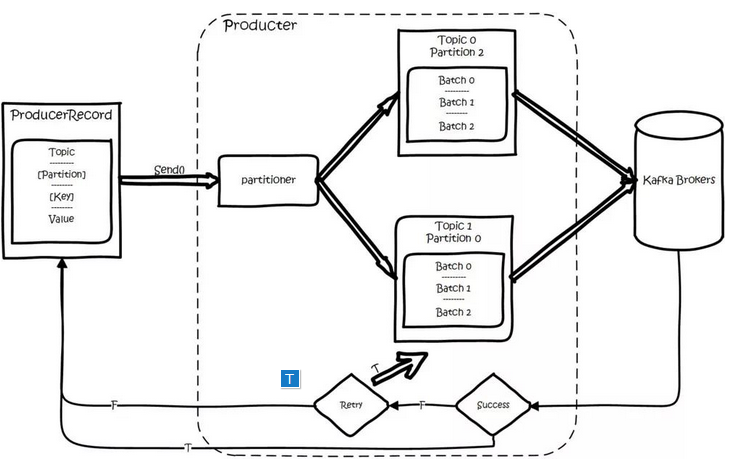
The producer will remain connected to all partition leaders under Topic, and messages will be sent directly from the producer to the broker via the socket. Where the location of the partition leader (host: port) is registered in zookeeper, the producer, as zookeeper client, has registered watch to listen for change events of the partition leader, so you can know exactly who the current leader is.
The producer side uses asynchronous sending: multiple messages are temporarily buffered on the client side and sent to the broker in bulk, with too much small data IO, slowing down the overall network latency, and bulk latency actually improving network efficiency.
(2) Data consumption process (Consume)
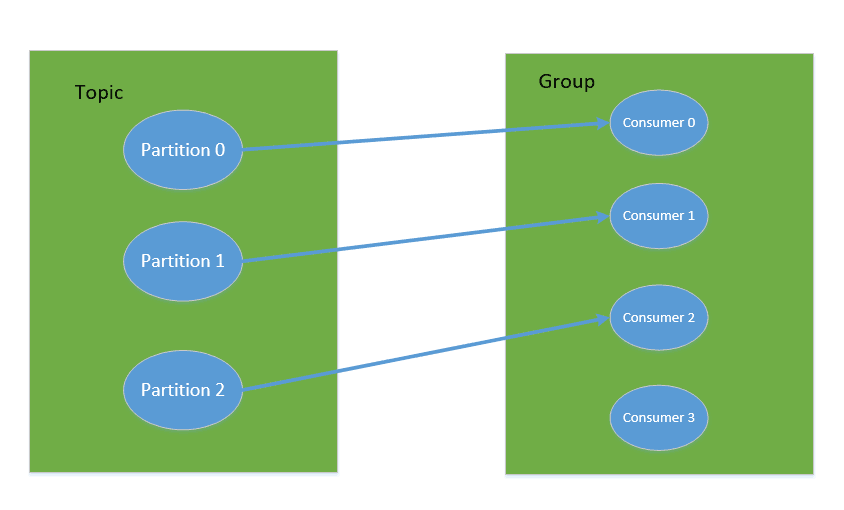
For consumers, it does not exist in a separate form, each consumer belongs to a consumer group, a group contains more than one consumer. In particular, it is important to note that subscription Topic is subscribed to as a consumption group, and messages sent to Topic are consumed by only one consumer in each group that subscribes to this Topic.
If all consumers have the same group, it's like a point-to-point messaging system, and if each consumer has a different group, the message is broadcast to all consumers.
Specifically, this is actually based on partition, a partition, can only be consumed by one consumer in the consumption group, but can be consumed by multiple consumer groups at the same time, each consumer in the consumer group is associated with a partition, so there is a saying: for a topic, the same group can not have more than partitions number of consumer consumption at the same time, otherwise it will mean some Consumer will not be able to get the message.
Two consumers in the same consumer group do not consume one partition at the same time.
In kafka, a pull approach is used, where consumer actively goes to pull (or fetch) messages after connecting to the broker, and first the consumer side can go fetch messages and process them in a timely manner according to their spending power, and can control the progress of message consumption (offset).
The message in partition has only one consumer at consumption, and there is no control over the message state, and there is no complex message confirmation mechanism, which shows that the kafka broker side is fairly lightweight. W hen the message is received by consumer, you need to save offset records where it was consumed, previously saved in ZK, because ZK's write performance is not good, the previous workaround is consumer every minute reported, after the 0.10 version, Kafka save this Offset, stripped from ZK, saved in a topic called consumeroffsets topic, thus visible, consumer The client is also lightweight.
4, messaging mechanism
Kafka supports three message delivery semantics, often using the At least once model in the business.
- At most once: At most, messages may be lost, but not repeated.
- At least once: At least once, messages are not lost and may be repeated.
- Exactly once: Only once, messages are not lost and not repeated, only consumed once.