Web Chinese font processing summary
May 30, 2021 Article blog
Table of contents
2. Use the web to customize fonts
3. 1. Chinese font size is too large and the load time is too long
4. Second, the font load is completed before the preview content is displayed
Background
In a Web project, using the right font can provide a good experience for users. B ut there are too many font files, and if you want to see the font effect, you can only open it one by one, which greatly affects your productivity. T herefore, you need to implement a feature that allows you to preview fonts based on fixed text and user input. There are two main issues that are addressed in the implementation of this function:
- Chinese font size is too large and the load time is too long
- The preview is not displayed until the font load is complete
Now summarize the solution of the problem and my thoughts.
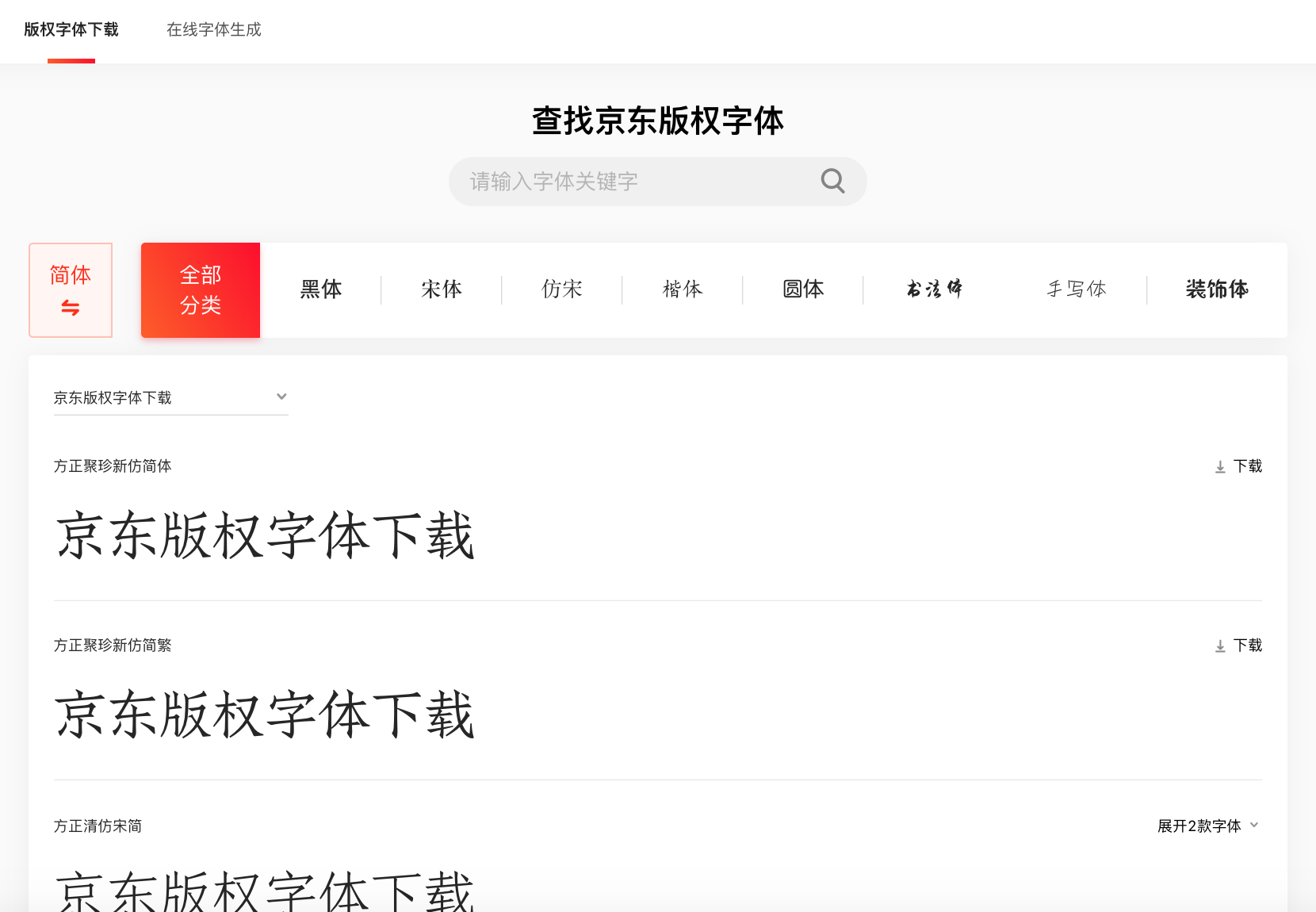
Use the web to customize fonts
Before we talk about these two issues, let's briefly describe how to use a web custom font. T
o use a custom font, you can rely on
@font-face
rules defined by
CSS Fonts Module Level 3.
Here's a basic way to use it that's compatible with all browsers:
@font-face {
font-family: "webfontFamily"; /* 名字任意取 */
src: url('webfont.eot');
url('web.eot?#iefix') format("embedded-opentype"),
url("webfont.woff2") format("woff2"),
url("webfont.woff") format("woff"),
url("webfont.ttf") format("truetype");
font-style:normal;
font-weight:normal;
}
.webfont {
font-family: webfontFamily; /* @font-face里定义的名字 */
}
Because
woff2
woff
and
ttf
formats are already well supported in most browsers, the code above can also be written as:
@font-face {
font-family: "webfontFamily"; /* 名字任意取 */
src: url("webfont.woff2") format("woff2"),
url("webfont.woff") format("woff"),
url("webfont.ttf") format("truetype");
font-style:normal;
font-weight:normal;
}
With
@font-face
rule, we simply upload the font source file to cdn, have the
url
value of
@font-face
rule as the address of the font, and finally apply this rule to the web text to preview the font.
But in doing so, we can clearly see a problem, font size is too large resulting in too long load time. We open the browser's Network panel to view:
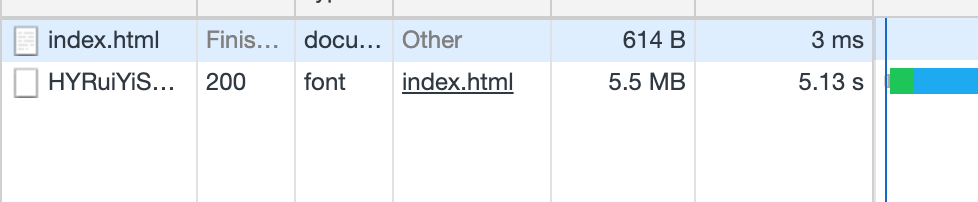
You can see that the font has a volume of 5.5 MB and a load time of 5.13 s. W hile many of the quark platforms Chinese font sizes between 20 and 40 MB, it can be expected that the load time will increase further. This wait time is not acceptable if the user is still in a weak network environment.
1. Chinese font size is too large and the load time is too long
1. Analysis of the reasons
So why is the Chinese font so large compared to the size of the English font, which is mainly due to two reasons:
- Chinese font contains a large number of glyphs, while English fonts contain only 26 letters and some other symbols.
- Chinese glyph lines are far more complex than English lines, and are used to control the position points of Chinese glyph lines more than English lines, so the amount of data is greater.
With
opentype.js
we can count the difference between the number of glyphs and the number of glyphs in a Chinese font and an English font:
| The font name | The number of glyphs | The number of bytes held by glyphs |
|---|---|---|
| FZQingFSJW_Cu.ttf | 8731 | 4762272 |
| JDZhengHT-Bold.ttf | 122 | 18328 |
Quark platform font previews need to be done in two ways, one is a fixed character preview, and the other is based on characters entered by the user. But either way, only a small number of characters will be used for the font, so it is not necessary to load the font in full, so we need to streamline the font file.
2. How to reduce the size of a font file
unicode-range
The unicode-range property is typically used in conjunction with
@font-face
rule, which controls the use of specific fonts for specific characters.
But it doesn't reduce the size of the font file, and interested readers can try it.
fontmin
fontmin
is a subset of fonts implemented by
JavaScript
As mentioned earlier, Chinese font size is larger than English font because it has more glyphs, then the idea of streamlining a font file is to remove useless glyphs:
// 伪代码
const text = '字体预览'
const unicodes = text.split('').map(str => str.charCodeAt(0))
const font = loadFont(fontPath)
font.glyf = font.glyf.map(g => {
// 根据unicodes获取对应的字形
})
In fact, thinning is not that simple, because a font file consists of many
表(table)that are associated with each other, such asmaxptable that records the number of glyphs and the offset of the glyph position stored in thelocatable. At the same time, the font file starts withoffset table(偏移表)whichoffset tableinformation for all tables in the font, so if we changeglyftable, we'll update the other tables at the same time.
Before we discuss how
fontmin
performs font interception, let's look at the structure of the font file:

The structure above is limited to a font file that contains only one font, and the glyph outline is based on
TrueType
format, which determines the value of
sfntVersion
so the offset table starts with
0字节
of the font file.
If the font file contains more than one font, the offset table for each font is specified in TTCHeader, which is outside the scope of the article.
Offset table:
| Type | Name | Description |
|---|---|---|
| uint32 | sfntVersion | 0x00010000 |
| uint16 | numTables | Number of tables |
| uint16 | searchRange | (Maximum power of 2 <= numTables) x 16. |
| uint16 | entrySelector | Log2(maximum power of 2 <= numTables). |
| uint16 | rangeShift | NumTables x 16-searchRange. |
Table record:
| Type | Name | Description |
|---|---|---|
| uint32 | tableTag | Table identifier |
| uint32 | checkSum | CheckSum for this table |
| uint32 | offset | Offset from beginning of TrueType font file |
| uint32 | length | Length of this table |
For a font file, whether its glyph outline is TrueType format or PostScript-based CFF format, it must contain tables such as
cmap
head
hhea
htmx
maxp
name
OS/2
post
I
f its glyph outline is trueType format, there are
cvt
fpgm
glyf
loca
prep
gasp
six tables will be used.
The six tables are optional except for
glyf
and
loca
Fontmin intercept glyph principle
fontmin
uses
fonteditor-core
internally, and the core font processing is left to this dependency,
fonteditor-core
main process is as follows:

1. Initialize reader
Convert font files to
ArrayBuffer
for subsequent reading of data.
2. Extract Table Directory
As we mentioned earlier, the structure immediately after
offset table(偏移表)
is table
table record(表记录)
and multiple
table record
are called
Table Directory
fonteditor-core
reads table
Table Directory
of the original font first, and we know from the structure recorded in the table above that each
table record
has four fields, each of which accounts for 4 bytes, so it is convenient to read with
DataView
and finally get all the table information for a font file as follows:
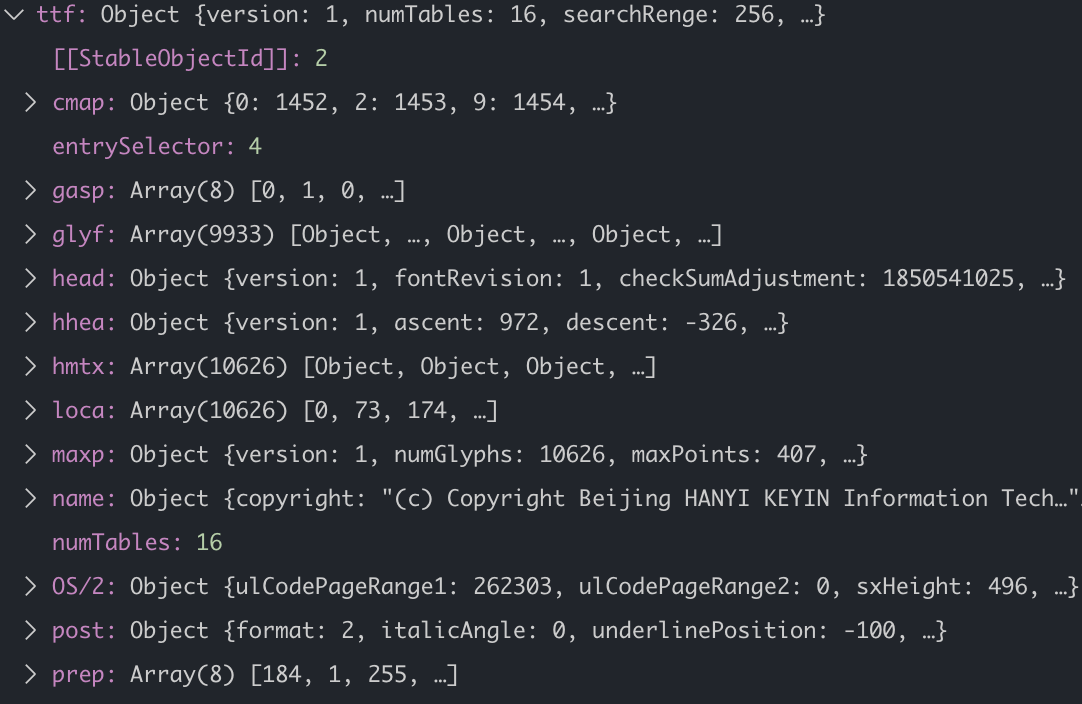
3. Read the table data
At this step, table data is read based on the offset and length information recorded by
Table Directory
T
he contents of
glyf
table are the most important for thin fonts, but
glyf
table record
only tells us the length of
glyf
table and the offset of
glyf
table relative to the entire font file, so how do we know the number, location, and size of
glyf
in the glyf table?
This requires specifying the number of glyphs with the
maxp
table and
loca(glyphs location)
table in the font, and the
loca
table records the offset of all glyphs from
glyf
table in the font as follows:
maxp
numGlyphs
| Glyph Index | Offset | Glyph Length |
|---|---|---|
| 0 | 0 | 100 |
| 1 | 100 | 150 |
| 2 | 250 | 0 |
| ... | ... | ... |
| n-1 | 1170 | 120 |
| extra | 1290 | 0 |
According to the specification, index
0
points to the missing
(missing character)
which is the character that appears when a character cannot be found in the font, which is usually represented by a blank box or space, and when the missing character does not have an outline, the
loca[n] = loca[n+1]
given according to the definition of the
loca
table.
We can find that one extra has
extra
added to the table above to calculate the length of the last glyph
loca[n-1]
The Offset field value in the table above is in bytes, but the exact number of bytes depends on the
indexToLocFormatfield value of the fontheadtable, when this value is0Offset 100 equals 200 bytes, and when this value is1Offset 100 is equal to 100 bytes, two different cases that correspond toShort versionLong versionin the font.
But just knowing the offset of all glyphs is not enough, and we can't recognize which glyph is what we need. S
uppose I need
字体预览
four glyphs, and the font file has ten thousand glyphs, and we know the offset of all glyphs through
loca
table, but which four blocks of data represent
字体预览
So we also need to use
cmap
table to determine the specific glyph location,
cmap
table records the character code
(unicode)
to the glyph index mapping, we get the corresponding glyph index, we can get the glyph offset in the
glyf
table based on the index.
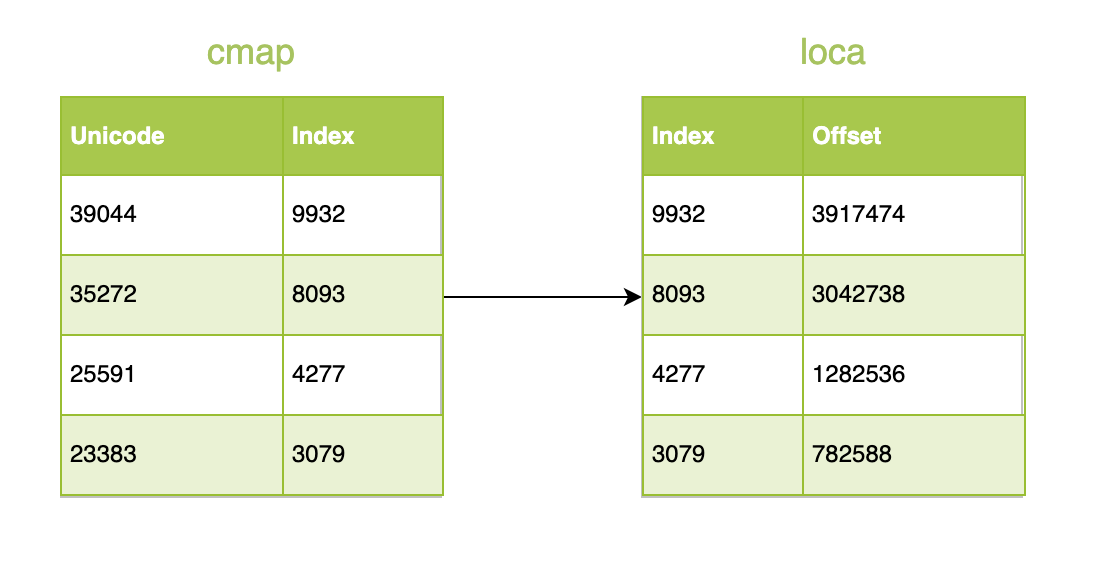
The data structure of a glyph begins with
Glyph Headers
| Type | Name | Description |
|---|---|---|
| int16 | numberOfContours | the number of contours |
| int16 | xMin | Minimum x for coordinate data |
| int16 | yMin | Maximum y for coordinate data |
| int16 | xMax | Minimum x for coordinate data |
| int16 | yMax | Maximum x for coordinate data |
numberOfContours
field specifies the number of outlines for this glyph, and the data structure immediately after
Glyph Headers
is
Glyph Table
In the definition of a font, the outline is made up of position points, and each location point has numbers, which start at
0
in ascending order.
So the glyph we read is to read the values in
Glyph Headers
and the position point coordinates of the outline.
In
Glyph Table
an array consisting of the number of the last position point for each profile is stored, from which you can find that the glyph has a total of several position points.
For example, if the value of this array is
[3, 6, 9, 15]
you can tell that the number of the last position point on the fourth outline is 15, then the glyph has a total of 16 position points, so we only need to traverse arrayBuffer
16
times for loop access to get the coordinate information of each location point, thus extracting the glyph we want, which is how
fontmin
is when intercepting glyphs.
In addition, when extracting coordinate information, the coordinate value of the other location points is not absolute except for the first location point, for example, the coordinates of the first point are
[100, 100]
the second read value is
[200, 200]
[200, 200]
[300, 300]
Because a font involves so many tables, and the data structure of each table is different. It is not possible to list how
fonteditor-corehandles each table.
4. Correlate glyf information
In fonts that use trueType outlines, each glyph provides the values of
xMin
xMax
yMin
and
yMax
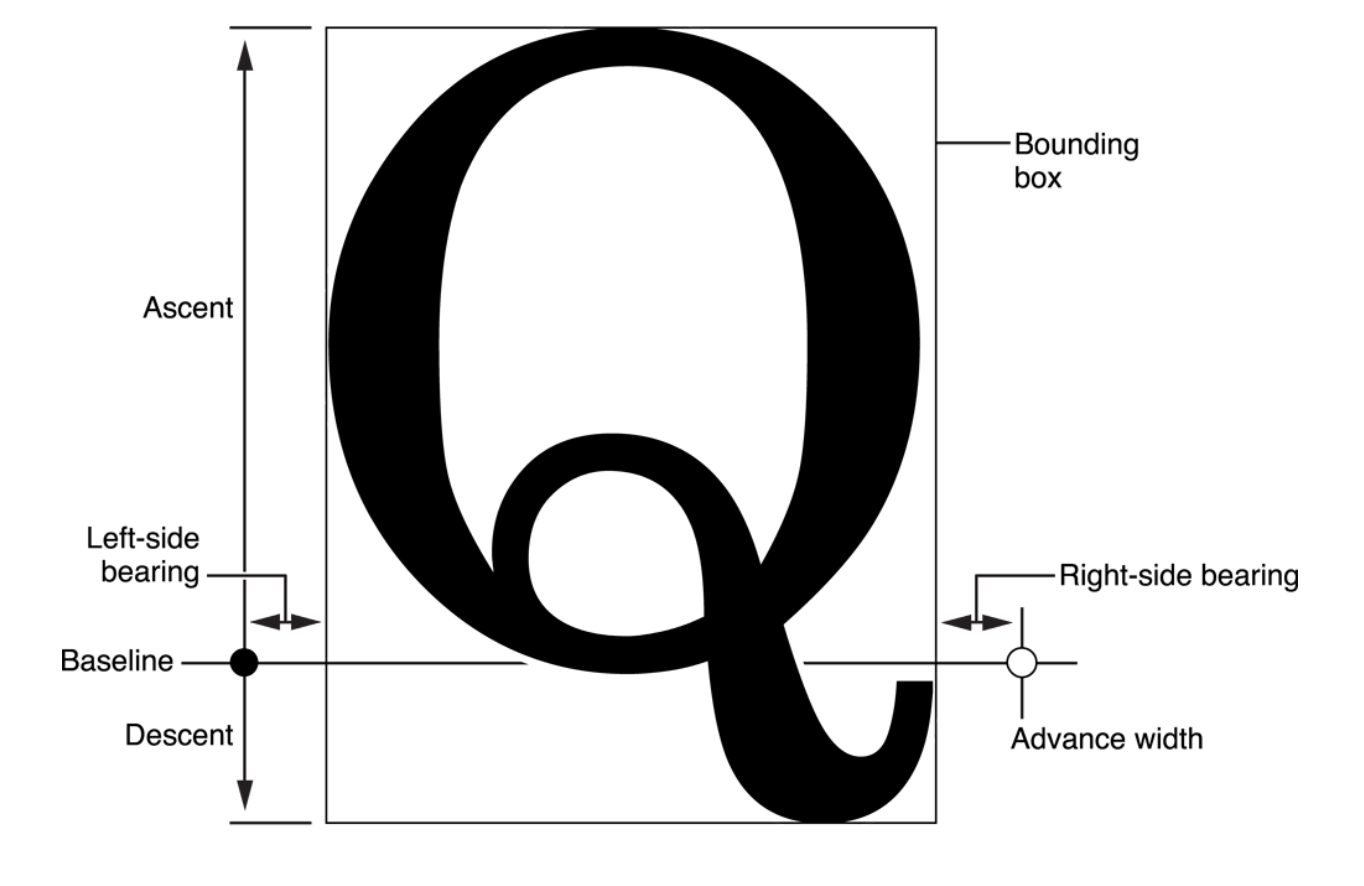
which are
Bounding Box
in the figure below. I
n addition to these four values, two fields,
advanceWidth
and
leftSideBearing
which are not in the
glyf
table and are therefore not available when the glyph information is intercepted.
In this step,
fonteditor-core
reads the
hmtx
table to get both fields.
5. Write the font
In this step, the size of the font file is recalculated and the values associated with
偏移表(Offset table)
and table
表记录(Table record)
are updated, and then the
偏移表
表记录
table
表数据
is written to the file in turn. I
t is important to note that when writing
表记录
you must write by table name order.
For example, if there are four tables:
prep
hmtx
glyf
head
the order of writing should be
glyf -> head -> hmtx -> prep
which is not required for
表数据
Fontmin deficiencies
fonteditor-core
only the fourteen tables mentioned above during the process of intercepting fonts, and the rest are discarded.
Each font typically also contains two tables,
vhea
and
vmtx
which control information such as the spacing of the font when it is in a vertical layout, which is lost when the font is intercepted with
fontmin
and the difference can be seen when the text is displayed vertically
(on the right is after the intercept):

Fontmin uses methods
Once we understand how
fontmin
works, we can use it happily.
After the server accepts the
fontmin
request from the client, the font is intercepted by
fontmin
returns the buffer corresponding to the intercepted font file, and don't forget that the font path in
@font-face
rule
base64
format, so we just need to embed the Buffer into
base64
format and return it to the client in
@font-face
and then the client inserts the
@font-face
into
<head></head>
label as CSS.
For fixed previews, we can also save the font file on the CDN, but the disadvantage of this approach is that if the CDN is unstable, the font load will fail. I
f, in the above method, each intercepted font exists as a
base64
string, you can make a cache on the service side, and there is no problem.
The font subset code generated with
fontmin
is as follows:
const Fontmin = require('fontmin')
const Promise = require('bluebird')
async function extractFontData (fontPath) {
const fontmin = new Fontmin()
.src('./font/senty.ttf')
.use(Fontmin.glyph({
text: '字体预览'
}))
.use(Fontmin.ttf2woff2())
.dest('./dist')
await Promise.promisify(fontmin.run, { context: fontmin })()
}
extractFontData()For fixed preview content we can pre-generate split fonts, and for dynamic preview content entered by users, of course we can follow this process:
Get input -> Intercept glyph -> Upload CDN -> generate @font-face -> insert page
Following this process, clients need to request twice to get font resources (don't forget to actually request fonts until
@font-face
inserts a page), and there's no better way
截取字形
and
上传 CDN
We know that the outline of a glyph is determined by a series of position points, so we can get the coordinates of the position points in
glyf
table and draw a particular glyph directly through
SVG
image.
SVGis a powerful image format that you can interact with usingCSSandJavaScriptwherepathelement is primarily applied
Getting location information and generating
path
tags we can do with
opentype.js
and once the client gets the
path
element that is entered into the glyph, it just needs to traverse the generated
SVG
label.
3. The advantages of reducing the size of font files
A comparison table of file size and load speed after font interception is attached below.
As you can see, fonts are loaded
145
times faster after being intercepted than when loaded in full.
fontminsupports the generation ofwoff2files, but the official documentation is not updated, and I started withwofffiles, butwoff2format files are smaller and browser support is good
| The font name | size | time |
|---|---|---|
| HanyiSentyWoodcut.ttf | 48.2MB | 17.41s |
| HanyiSentyWoodcut.woff | 21.7KB | 0.19s |
| HanyiSentyWoodcut.woff2 | 12.2KB | 0.12s |
Second, the font load is completed before the preview content is displayed
This is the second problem in implementing the preview function.
There are two concepts in the browser's font display behavior,
阻塞期
and
交换期
in the case of
Chrome
there is a period of time before the font is loaded, which is called
阻塞期
I
f the load is still not completed during the
阻塞期
the fallback font is displayed first, enters the
交换期
and waits for the font to be replaced when the load is complete. T
his causes the page font to flash, which doesn't match the effect I want.
And the
font-display
property controls this behavior of the browser, can we change the value of the
font-display
property to achieve our purpose?
font-display
| Block Period | Swap Period | |
|---|---|---|
| block | Short | Infinite |
| swap | None | Infinite |
| fallback | Extremely Short | Short |
| optional | Extremely Short | None |
The display policy of the font is related to the value of
font-display
and the browser's default
font-display
value is
auto
which behaves closely to the value
block
The first strategy is
FOIT(Flash of Invisible Text)FOITdefault representation of a browser when loading fonts, whose rules are as mentioned earlier.
The second strategy is
FOUT(Flash of Unstyled Text)FOUTinstructs the browser to use the fallback font until the custom font is loaded, with a value ofswap
Apps with two different strategies: Google Fonts FOIT Hanyi Word Library FOUT
In a quark project, I want the effect to be that the preview is not displayed until the font is loaded, and the
FOIT
strategy is the closest.
However, the maximum time
FOIT
text content is not visible is
3s
and if the user's network is not in good condition, the back-up font is displayed after
3s
causing the page font to blink, so
font-display
property does not meet the requirements.
As you can see,
the CSS Font Loading API
also provides solutions at the
JavaScript
level:
FontFace、FontFaceSet
Let's first look at their compatibility:
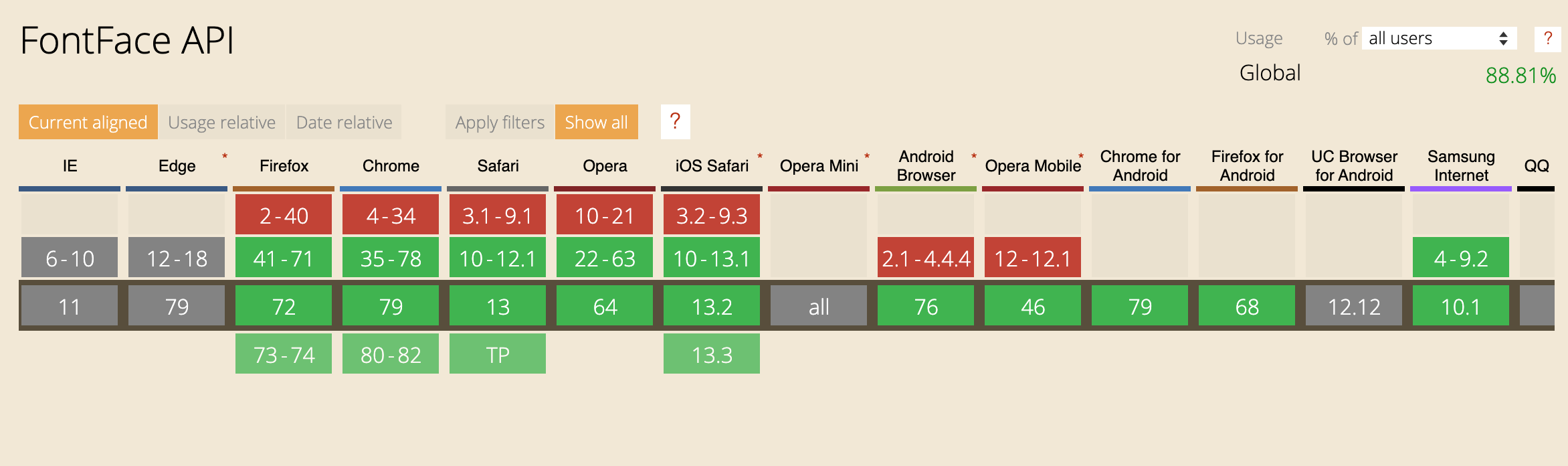
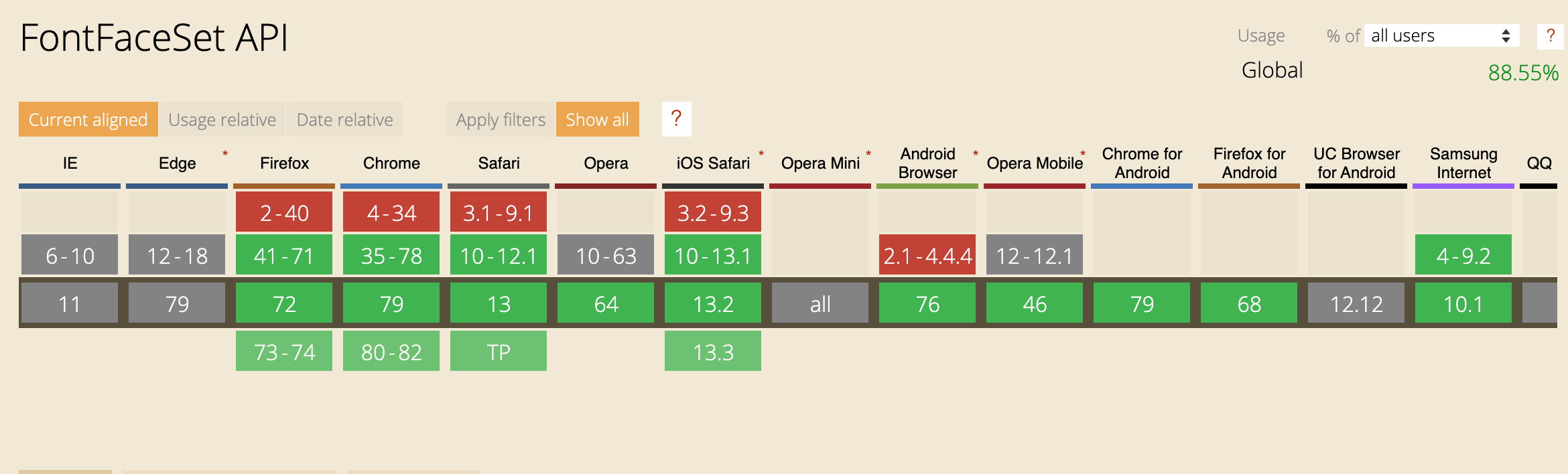
It's IE again, and IE doesn't have a user to worry about
We can construct a
FontFace
object from the
FontFace
constructor:
const fontFace = new FontFace(family, source, descriptors)
-
family
-
Font name, specifying a name as the value of the
CSSpropertyfont-family
-
Font name, specifying a name as the value of the
-
source
-
The font source, which can be a
urlorArrayBuffer
-
The font source, which can be a
-
descriptors
optional-
style:
font-style -
weight:
font-weight -
stretch:
font-stretch -
display:
font-display(this value can be set, but will not take effect). -
unicodeRange:
@font-faceunicode-ranges -
variant:
font-variant -
featureSettings:
font-feature-settings
-
style:
FontFace is not loaded after a
fontFace
is constructed, and
fontFace
load
method must be executed.
load
method returns a
promise
and the
resolve
value of
promise
is the font after it has been loaded successfully.
However, just loading successfully does not make this font effective, and the returned
fontFace
needs to be added to
fontFaceSet
Here's how to use it:
/**
* @param {string} path 字体文件路径
*/
async function loadFont(path) {
const fontFaceSet = document.fonts
const fontFace = await new FontFace('fontFamily', `url('${path}') format('woff2')`).load()
fontFaceSet.add(fontFace)
}
Therefore, when the client can set the CSS of the text content to
opacity: 0
wait for
await loadFont(path)
to be executed, and then set the CSS to
opacity: 1
so that we can control that the content is not displayed until the custom font load is complete.
Final summary
This article describes the problems and solutions encountered in developing font preview functionality, limited to
OpenType
specification entries, and in the Introduction
fontmin
Principles section, only describes the handling of
glyf
tables, which interested readers can learn more about.
This work review and summary process, but also thinking about better implementation, if you have suggestions welcome to communicate with me. At the same time the content of the article is my personal understanding, there are errors difficult to avoid, if found errors welcome to correct.
Thanks for reading!
reference
- Front-end font interception
- Scalable Vector Graphics
- FontFace
- FontFaceSet
- fontmin
- fonteditor-core
- TrueType-Reference-Manual
- OpenType-Font-File
Author: Lin Lin
Source: Bump Lab