Spark Streaming
May 17, 2021 Spark Programming guide
Table of contents
Spark Streaming
Spark streaming is an extension of Spark Core API, which is scalable, high throughput, and fault-lerable for real-time streaming data processing. W e can get data from kafka, flume, Twitter, ZeroMQ, Kinesis, etc., or we can calculate data from complex algorithms consisting of high-order functions map, reduce, join, window, etc. F inally, the processed data can be pushed to the file system, database, real-time dashboard. In fact, you can apply the processed data to Spark's machine learning algorithms, graph processing algorithms.

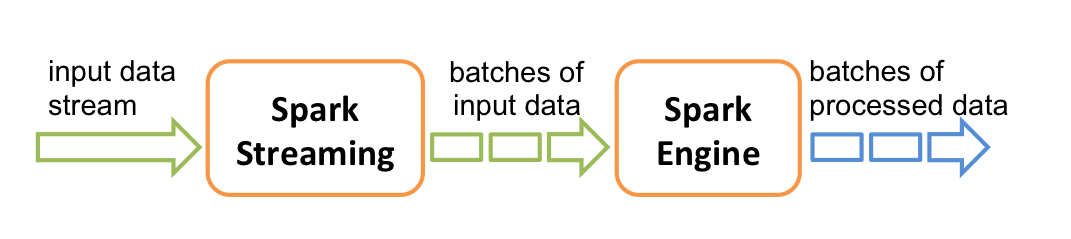
Internally, it works as shown in the following illustration. Spark Streaming receives real-time input data streams, which are then sliced into batches for the Spark engine to process, which generates the final result data.
Spark Streaming supports a high-level abstraction called
discretized stream
DStream
represents a continuous stream of data. D
Stream can be created from input data streams obtained from sources such as Kafka, Flume, and Kinesis, or by higher-order functions based on other DStreams.
Internally, DStream is made up of a series of RDDs.
This guide guides users to start writing Spark Streaming programs using DStream. Users can write Spark Streaming programs using scala, java, or Python.
Note: Spark 1.2 has introduced the Python API for Spark Streaming. A ll of its DStream transformations and almost all of its output operations can be used in scala and java interfaces. H owever, it only supports basic sources such as text files or text data on sockets. APIs from external sources such as flume and kafka will be introduced in the future.