Spark GraphX property map
May 17, 2021 Spark Programming guide
Table of contents
Spark GraphX property map
A property graph is a directed multi-graph with user-defined objects connected to each verte and edge. T here are edges that share the same source and destination vertes to multiple parallel edges in multiple diagrams. T he ability to support parallel edges simplifies the modeling scenario, where the same vertes have multiple relationships (such as co-worker and friend). E ach vertex is keyed by a unique 64-bit long identifier (VertexID). G raphX does not impose any sorting on vertemo identity. Similarly, vertvertes have the appropriate source and destination vertred identifiers.
Property diagrams are parameterized by vertex (VD) and edge (ED) types, which are the types of objects associated with each vertex and edge, respectively.
In some cases, in the same drawing, you might want vertes to have different property types. T his can be done through inheritance. For example, modeling users and products into a two-part diagram, we can do this in the following way
class VertexProperty()
case class UserProperty(val name: String) extends VertexProperty
case class ProductProperty(val name: String, val price: Double) extends VertexProperty
// The graph might then have the type:
var graph: Graph[VertexProperty, String] = nullLike RDD, property diagrams are imm changed, distributed, and fault-compated. A change in the value or structure of a graph needs to be implemented by generating a new graph as expected. N ote that most of the original diagram can be reused in the new diagram to reduce the cost of this inherent functional data structure. T he performer uses a series of vertest partition heditations to partition the graph. Like RDD, each partition in the figure can be recreated on a different machine in the event of a failure.
The logical property graph corresponds to a pair of typed collections (RDDs) that encode the properties of each verte and edge. Therefore, the graph class contains members that access the vertes and edges in the graph.
class Graph[VD, ED] {
val vertices: VertexRDD[VD]
val edges: EdgeRDD[ED]
}
VertexRDD[VD]
and
EdgeRDD[ED]
are inherited and optimized from
RDD[(VertexID, VD)]
and
RDD[Edge[ED]]
VertexRDD[VD]
EdgeRDD[ED]
additional functionality to build on graph calculations and utilize internal optimization.
An example of a property diagram
In the GraphX project, let's say we want to construct a property diagram that includes different collaborators. V ertes properties may contain user names and occupations. We can label edges with strings that describe the relationship between collaboraters.
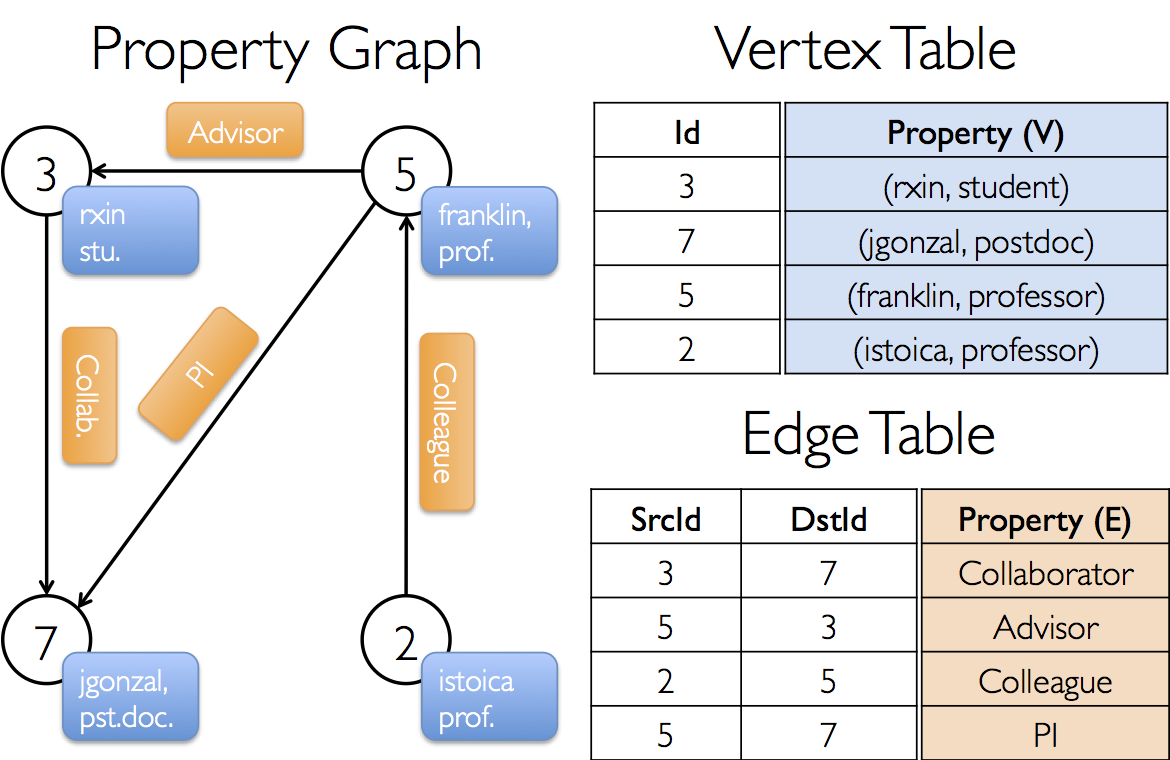
The resulting graphic will have a type signature
val userGraph: Graph[(String, String), String]There are many ways to construct a property graph from an original file, RDD. T he most common approach is to take advantage of Graph object. The following code generates a property map from the RDD collection.
// Assume the SparkContext has already been constructed
val sc: SparkContext
// Create an RDD for the vertices
val users: RDD[(VertexId, (String, String))] =
sc.parallelize(Array((3L, ("rxin", "student")), (7L, ("jgonzal", "postdoc")),
(5L, ("franklin", "prof")), (2L, ("istoica", "prof"))))
// Create an RDD for edges
val relationships: RDD[Edge[String]] =
sc.parallelize(Array(Edge(3L, 7L, "collab"), Edge(5L, 3L, "advisor"),
Edge(2L, 5L, "colleague"), Edge(5L, 7L, "pi")))
// Define a default user in case there are relationship with missing user
val defaultUser = ("John Doe", "Missing")
// Build the initial Graph
val graph = Graph(users, relationships, defaultUser)
In the example above, we used the
Edge
sample class. T
he edge has an
srcId
dstId
the source and target vertes, respectively.
In addition,
Edge
class has an
attr
that stores edge properties.
We can
graph.vertices
graph.edges
members, respectively.
val graph: Graph[(String, String), String] // Constructed from above
// Count all users which are postdocs
graph.vertices.filter { case (id, (name, pos)) => pos == "postdoc" }.count
// Count all the edges where src > dst
graph.edges.filter(e => e.srcId > e.dstId).count注意,graph.vertices返回一个VertexRDD[(String, String)],它继承于 RDD[(VertexID, (String, String))]。所以我们可以用scala的case表达式解构这个元组。另一方面,
graph.edges返回一个包含Edge[String]对象的EdgeRDD。我们也可以用到case类的类型构造器,如下例所示。
graph.edges.filter { case Edge(src, dst, prop) => src > dst }.count
In addition to the vertes and edge views of the property graph, GraphX also contains a omton view that logically
RDD[EdgeTriplet[VD, ED]]
of the vertes and edges as an instance of the
EdgeTriplet
class.
This connection can be represented by the sql expression below.
SELECT src.id, dst.id, src.attr, e.attr, dst.attr
FROM edges AS e LEFT JOIN vertices AS src, vertices AS dst
ON e.srcId = src.Id AND e.dstId = dst.IdOr by the figure below.

EdgeTriplet
class inherits
Edge
class and
srcAttr
and
dstAttr
members, which contain the properties of the source and destination, respectively.
We can render a collection of strings with a triple view to describe the relationships between users.
val graph: Graph[(String, String), String] // Constructed from above
// Use the triplets view to create an RDD of facts.
val facts: RDD[String] =
graph.triplets.map(triplet =>
triplet.srcAttr._1 + " is the " + triplet.attr + " of " + triplet.dstAttr._1)
facts.collect.foreach(println(_))