Meteor publishes and subscribes
May 09, 2021 Meteor
Table of contents
Publish and subscribe
Publishing and subscription are one of Meteor's most basic and important concepts, but it's also a bit difficult if you're new to Meteor.
This has led to a number of misconceptions, such as the view that Meteor is unsafe, or that meteor applications cannot handle large amounts of data, and so on.
People get confused about these concepts at first, in large part because Meteor does a lot for you like magic. A lthough these magics ultimately seem to work, they mask what the background really does (like magic). So let's peel off the magic to see what's going on.
Past days
First, let's look back at the days before 2011, when Meteor was not born. L et's say we're going to build a simple Rails app. When a user comes to our site, the client (for example, a browser) sends a request to our server-side app.
The app's first task is to figure out what data the customer is requesting. T his could be page 12 of the search results, Mary's user information, Bob's 20 most recent tweets, and so on. Think of being a bookstore guy between bookshelves to help you find the book you're looking for.
When the correct data is found, the app's next task is to convert the data into a good-looking, human-readable HTML format (for the API, the JSON string).
Using a bookstore as an example, it's like packing the bag you just bought and packing it in a nice bag. This is the view part of the famous MVC (model-view-controller) pattern.
Eventually, the app sends the HTML code to the client. T he app's tasks are gone. It can buy a bottle of beer and wait for the next request.
Meteor's way
Let's see how special Meteor is in contrast. As we can see, meteor's key innovation is that rails programs only run on the server, and a Meteor App includes client components that run on the client (browser).
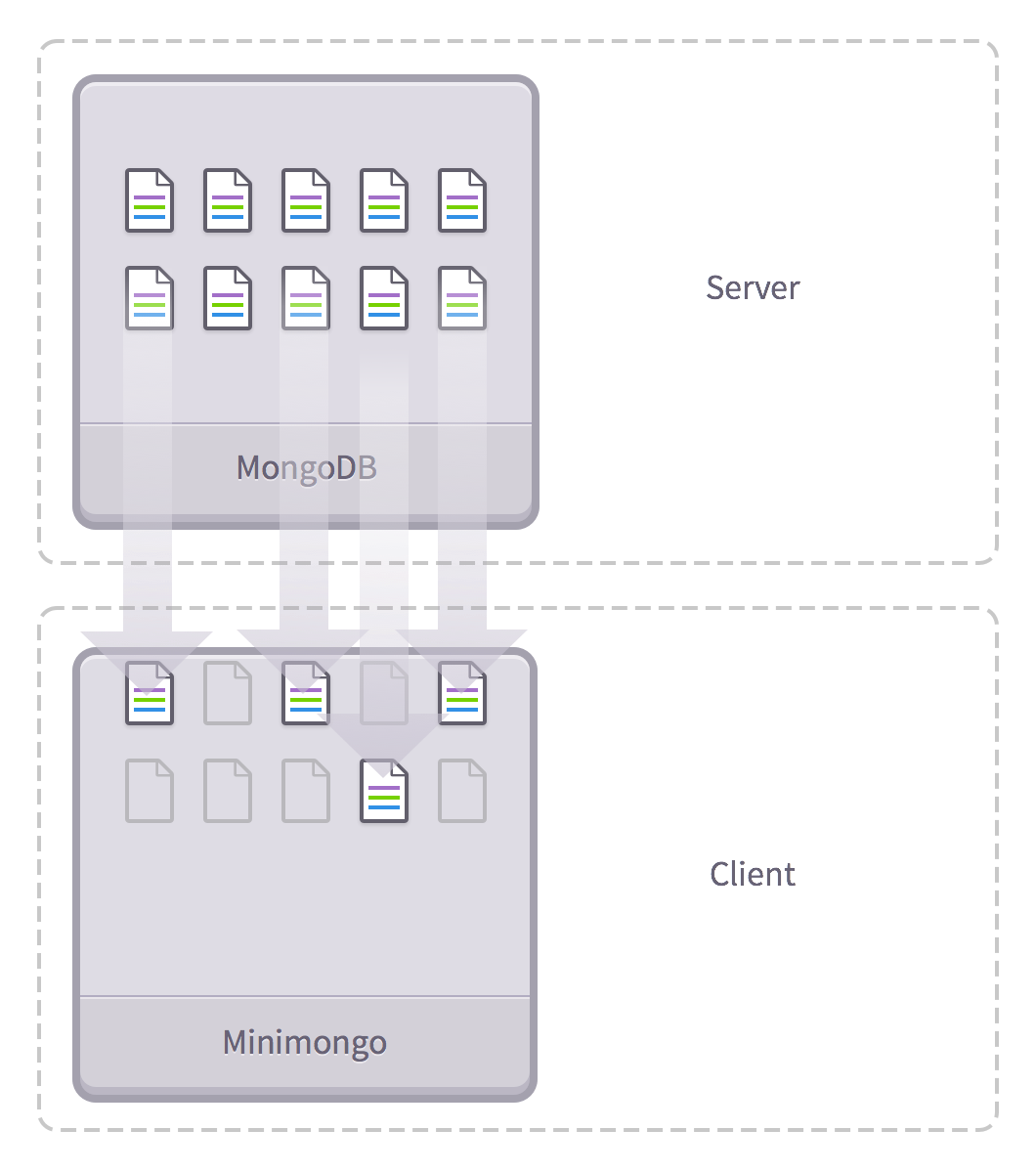
Push a subset of the database to the client
It's the equivalent of a bookstore guy not only helping you find a book in the bookstore, but also going home with you and reading it to you every night (which sounds weird).
This architecture allows Meteor to do more cool things, and one of the main things is that Metoer becomes database-ubiquitous. Simply put, Meteor took out a subset of your data and copied it to the client.
The second two main results are: First, instead of sending HTML code to the client, the server sends the real raw data, allowing the client to decide what to do with the online data. Second, instead of waiting for the server to pass back the data, you can access or even modify the data immediately (delay compensation latency compensation).
Release
An app's database can use tens of thousands of data, some of which can also be private and confidential sensitive data. Obviously we can't simply mirror the database to the client, whether for security reasons or scalability reasons.
So we need to tell Meteor that those subsets of data need to be sent to the client, and we're going to do that with the Publish feature.
Let's go back to Microscope. Here are all the posts in our app database:
 All post data in the database
All post data in the database
Although it doesn't actually exist, we assume that several of our posts have been specially tagged for inappropriate speech. We need to leave them in the database but we don't want the user to see them (send them to the client).
Our first task was to tell Meteor that the data we were sending to the client. We told Meteor that we only post unst marked posts.
 Exclude posts that have been tagged
Exclude posts that have been tagged
Here is the corresponding code, in the server-side code.
// 在服务器端
Meteor.publish('posts', function() {
return Posts.find({flagged: false});
});This ensures that the client will not be able to see the tagged post anyway. That's how meteor apps are secure: Make sure you publish only the data you let this current user see.
Ddp
Basically, we can think of the publish/subscribe pattern as a funnel that filters data from the server side (data source) to the client (target).
This funnel's proprietary protocol is called DDP (the abbreviation for distributed data protocol Distributed Data Protocol). For more details about DDP, you can learn more about the concept by watching Matt DeBergalis's lecture video at the Real-time conference, or this screen capture from Chris Mather.
Subscription
Even if we want to send tagged posts to the client, we can't send thousands of posts out of our head. We need a mechanism for clients to determine which subsets they particularly need at some point, and that's what subscriptions do.
With MiniMongo, the client MongoDB app, the data you subscribe to is mirrored to the client.
For example, let's take a look at Bob Smith's personal page, which will only show his posts.
 Posts that subscribe to Bob are mirrored to the client
Posts that subscribe to Bob are mirrored to the client
First, let's add a parameter to the release function:
// 在服务器端
Meteor.publish('posts', function(author) {
return Posts.find({flagged: false, author: author});
});Then we define the same parameter when the client subscribes to this publication.
// 在客户端
Meteor.subscribe('posts', 'bob-smith');That's why we make the Meteor program scalable on the client side: instead of subscribing to all the data, we're choosing the data you need now to subscribe. In this way, you can avoid consuming large amounts of client-side memory, regardless of the total amount of data on the server side.
Find
Bob's posts now happen to cover several categories (such as JavaScript, Ruby, and Python). M aybe we still need to put all of Bob's posts in memory, but we just want to show posts that fall into the JavaScript category right now. That's what Find is for.
 Select a subset of the data on the client
Select a subset of the data on the client
As we did on the server, we used the
Posts.find()
select a subset of the data:
// 在客户端
Template.posts.helpers({
posts: function(){
return Posts.find({author: 'bob-smith', category: 'JavaScript'});
}
});Now that we understand the subscription and publishing mechanisms, let's take a closer look at some common application patterns.
Auto-publish
If you start a Meteor project from scratch (for example,
meteor create
a package called
autopublish
and enabled.
Let's talk about what this bag is for.
autopublish
is to give the Meteor application a simple start-up phase, which simply mirrors all the data on the server directly to the client, so you don't have to publish and subscribe.
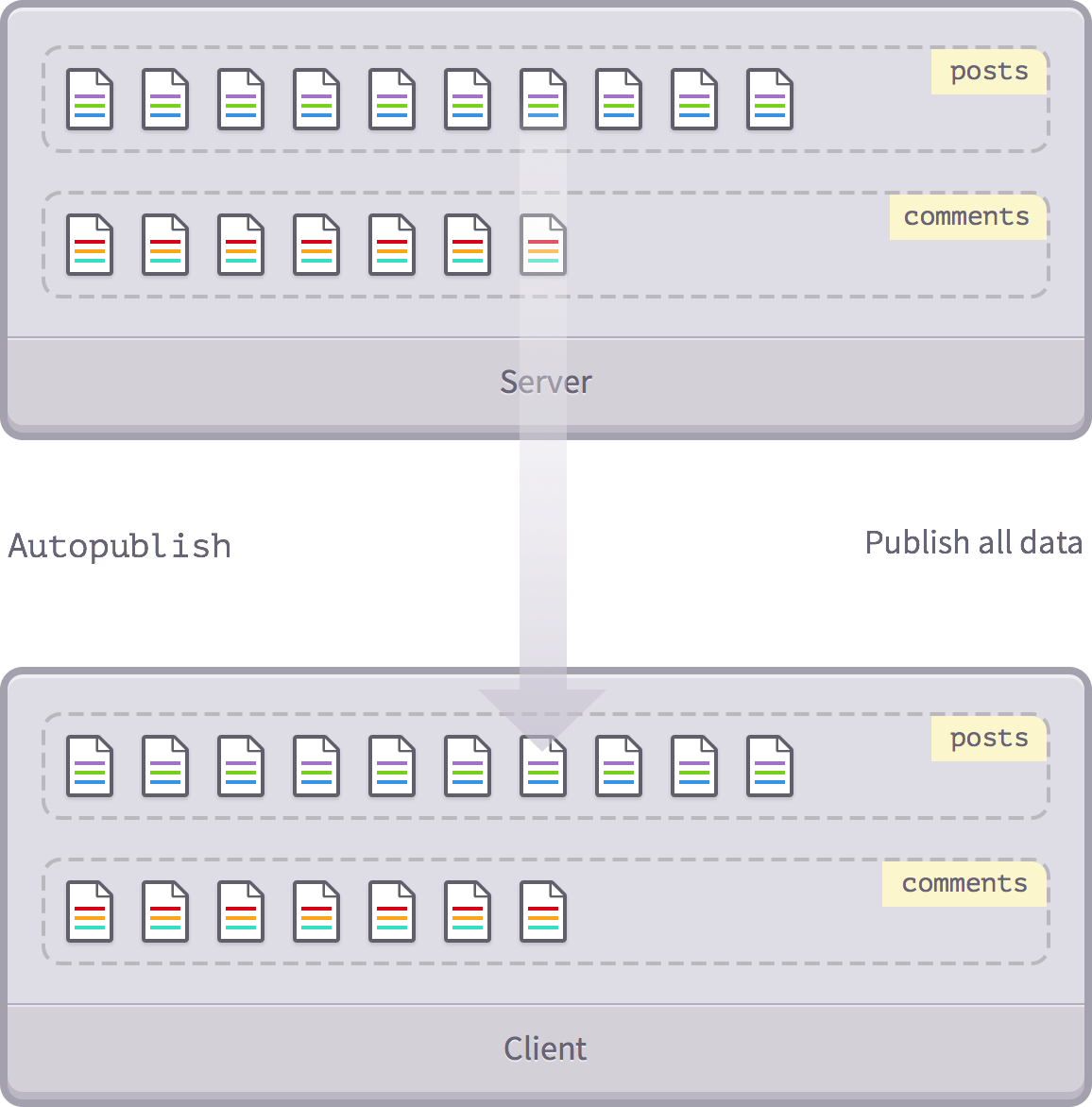 Auto-publish
Auto-publish
So how exactly does this work? S
uppose we have a collection on the server side called
posts
The automatic publishing package automatically sends all the data (posts) from this collection in the Mongo database
‘posts’
the client does have such a collection).
So if you use auto-publishing, you don't need to think about publishing. T he data is consistent, and things get easier. Of course, the obvious problem with this is that all your data is cached on all users' computers.
For this reason, auto-publishing is only used when you're in your infancy and haven't considered publishing yet.
Publish all collections
Once you delete the
autopublish
you'll soon find that there's no data on your browser. A
n easy solution is to repeat what auto-publishing does, and that's to publish all the data.
Like what:
Meteor.publish('allPosts', function(){
return Posts.find();
});
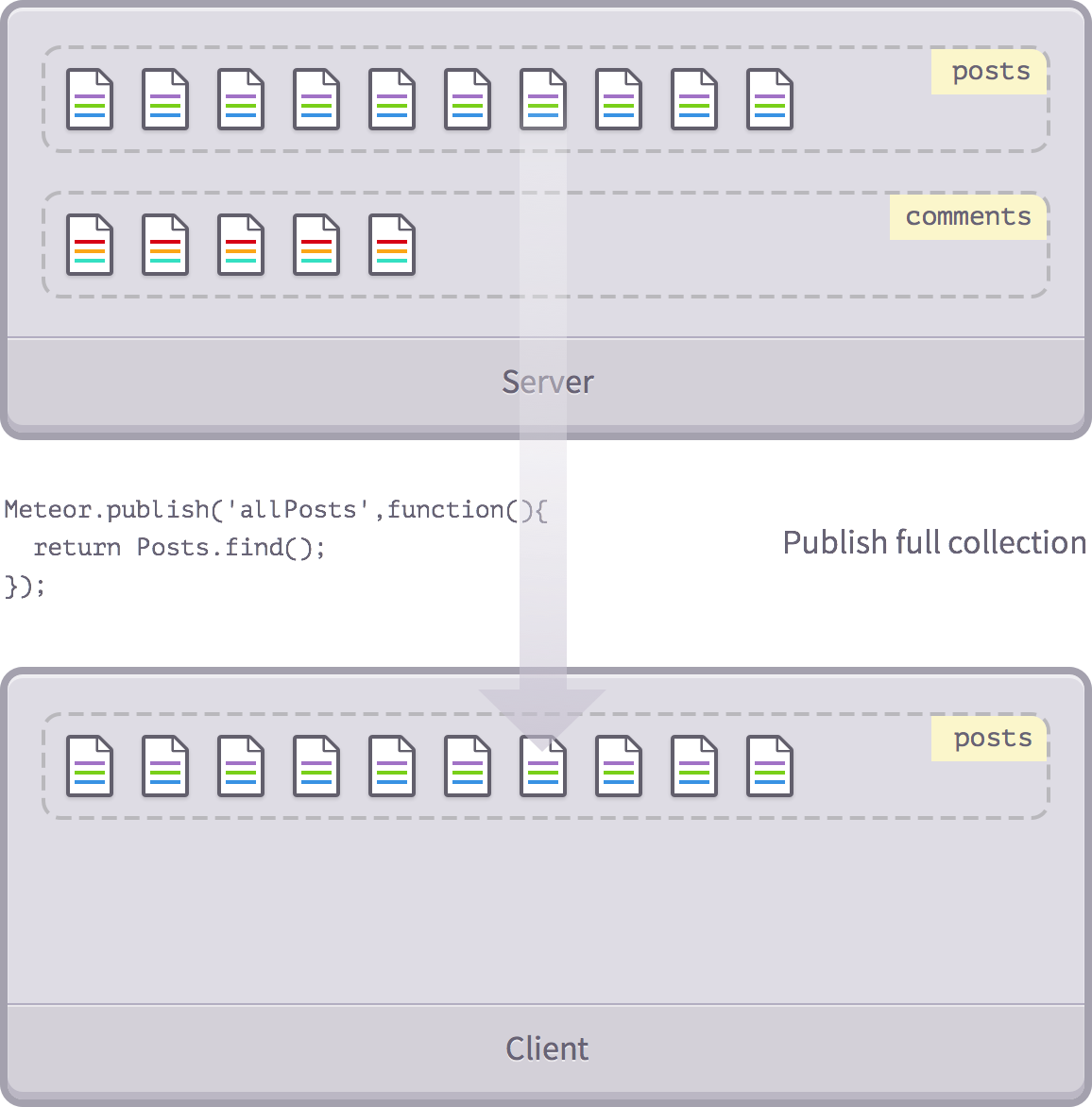 Publish all collections
Publish all collections
We still publish all the collections, but at least we can now control which collection we publish and which we don't.
For example, for now, we published
Posts
collection but didn't
Comments
Publish part of the collection
The next thing we're going to do is publish the part of the collection. For example, we only post posts from an author:
Meteor.publish('somePosts', function(){
return Posts.find({'author': 'Tom'});
});
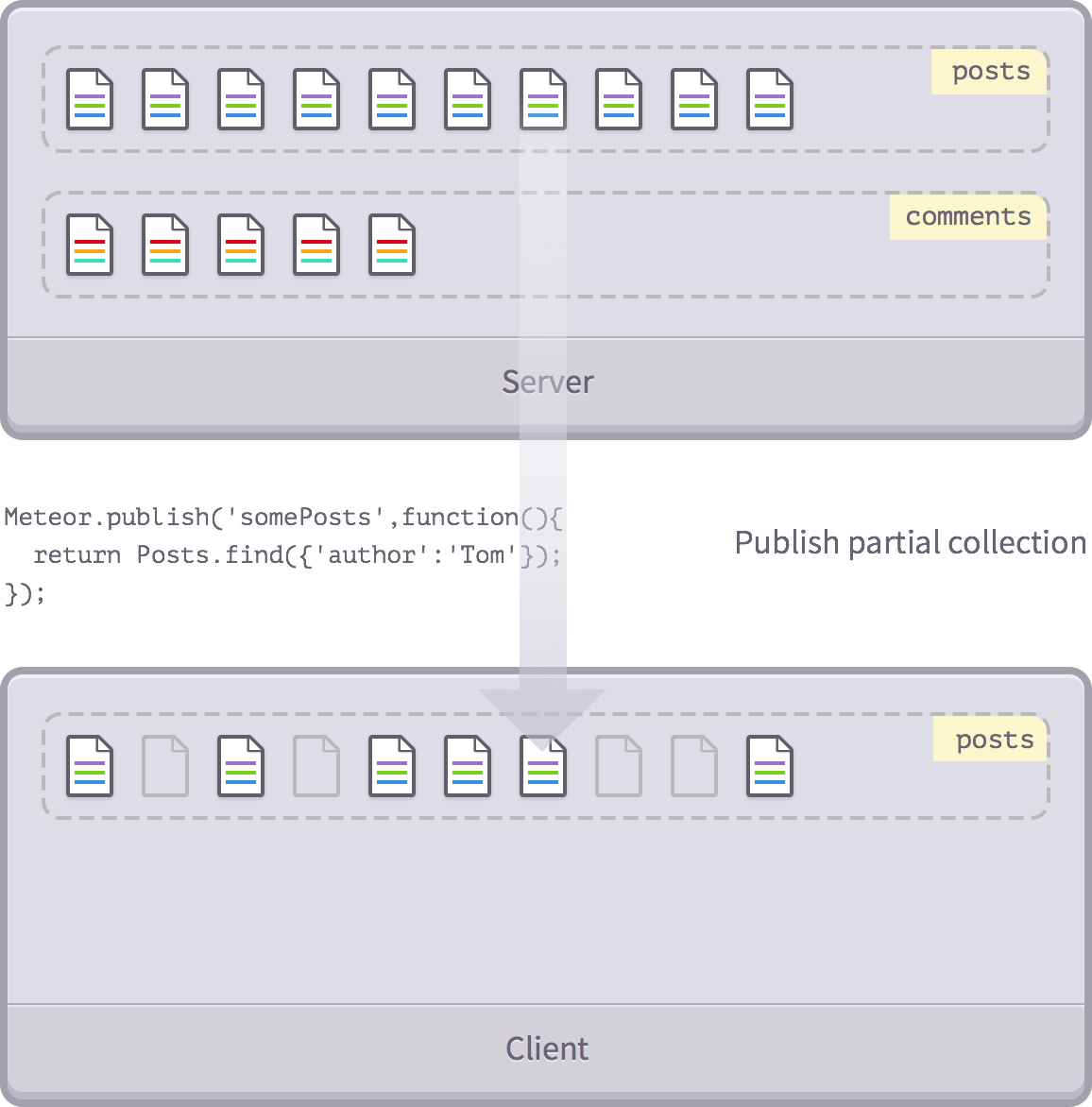 Part of the publishing collection
Part of the publishing collection
Behind the scenes
If you've read
the Meteor publishing document,
added()
and
ready()
that set client record properties, and you're tangled up in the fact that we never seem to have used these methods.
The reason is that Meteor provides a very important
_publishCursor()
approach. Y
ou don't see us using this method, do you?
Maybe we didn't use it directly, but if you returned a cursor in the publishing function (for example,
Posts.find({'author':'Tom'})
when Meteor used this method.
When Meteor
somePosts
publishing function returns a cursor,
_publishCursor()
to -- guess what -- to automatically publish the cursor.
_publishCursor()
():
- It checks the name of the collection on the server side
-
It finds all the documents that meet the requirements from the cursor and sends them to the
client's collection of
the same name.
(It is done
.added()function) -
When a new document is added to the collection, or deleted or changed, it sends those changes to the collection of the client.
(It uses
.observe()monitor cursors,.added().changed()removed()to add and remove.
So in the example above, we can guarantee that users will only get posts of interest to them in the client cache (in this case, Tom's post).
Publish some fields
We've seen how to post some posts, but we need to streamline them! Let's see how to publish only the specified part of the field.
As before we used
find()
to return a cursor, now let's remove some fields.
Meteor.publish('allPosts', function(){
return Posts.find({}, {fields: {
date: false
}});
});
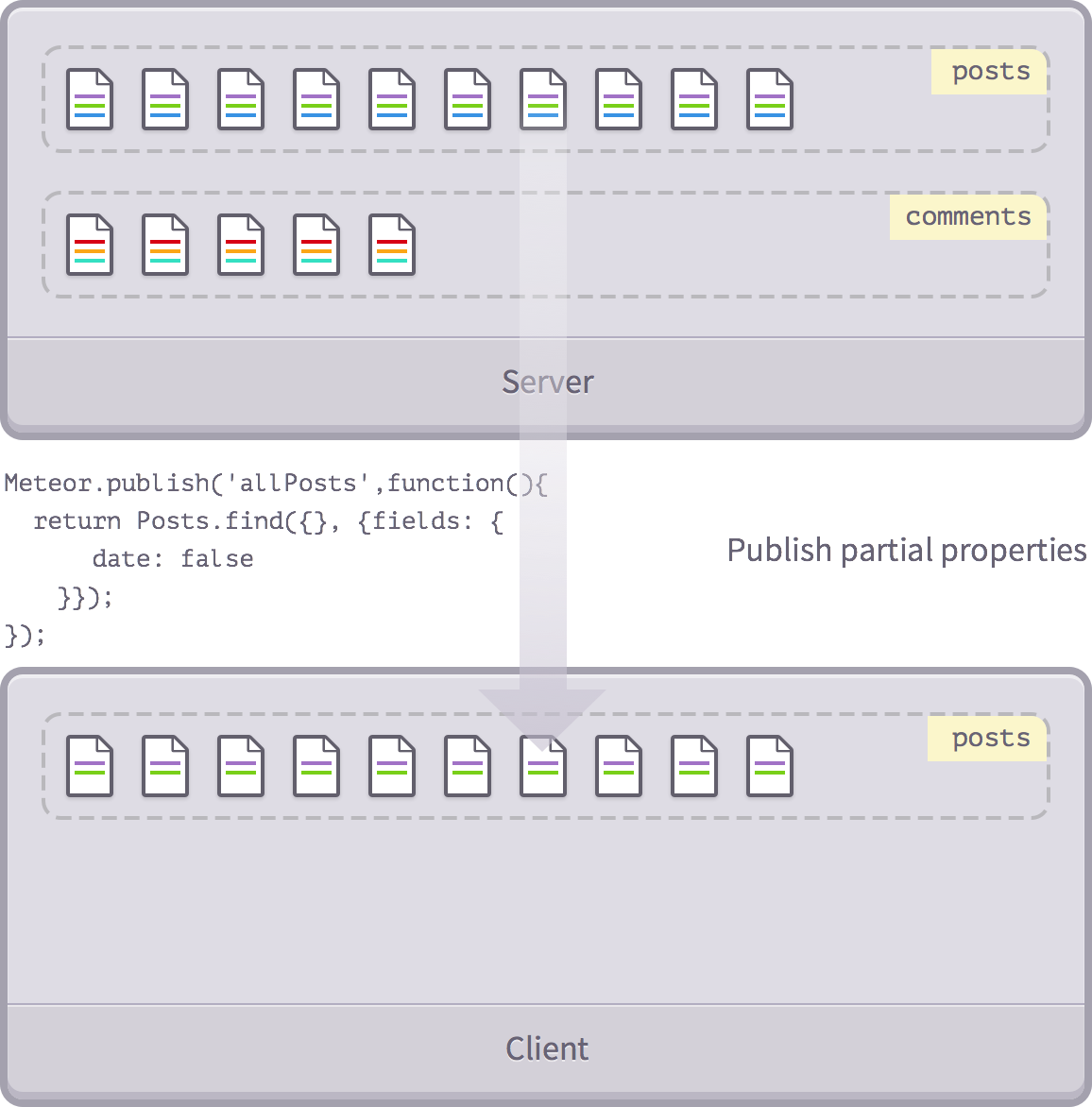 Publish some fields
Publish some fields
In fact, we can use both techniques, post only posts by Tom, and hide the date date field:
Meteor.publish('allPosts', function(){
return Posts.find({'author': 'Tom'}, {fields: {
date: false
}});
});Summarize
We've 3d everything from publishing all the fields of all documents in all collections (via
autopublish
to publishing the individual fields of the individual collections.
This already covers the basics of Meteor's publishing, and these basic techniques are sufficient to cover most use cases.
Sometimes you need to further combine, connect, or converg publish. We'll talk about this in a later chapter!