Meteor advanced publishing mechanism
May 10, 2021 Meteor
Table of contents
1. Advanced publishing mechanism
2. Publish a collection multiple times
3. Subscribe to one publication multiple times
Advanced publishing mechanism
For now, you should have a good grasp of publishing and subscription interaction patterns. So let's talk less nonsense and look at a few more advanced scenarios.
Publish a collection multiple times
In our first appendix to release, we saw some of the more general publishing and
_publishCursor
to make them very easy to implement on our site.
First,
_publishCursor
has done for us: it will organize all the documents to match a given cursor and push them into the client
collection
with the same name.
Note that this is
not related
to the publication's name.
This means that we can connect the client and service-side versions of any collection with more than one publicaton.
We've already used this pattern in the page section, and when we're outside of the posts we're currently displaying, we're posting a subset of the paged versions of all posts.
Another similar use case is to publish a preview of a large set of documents, and the full information for a single document:
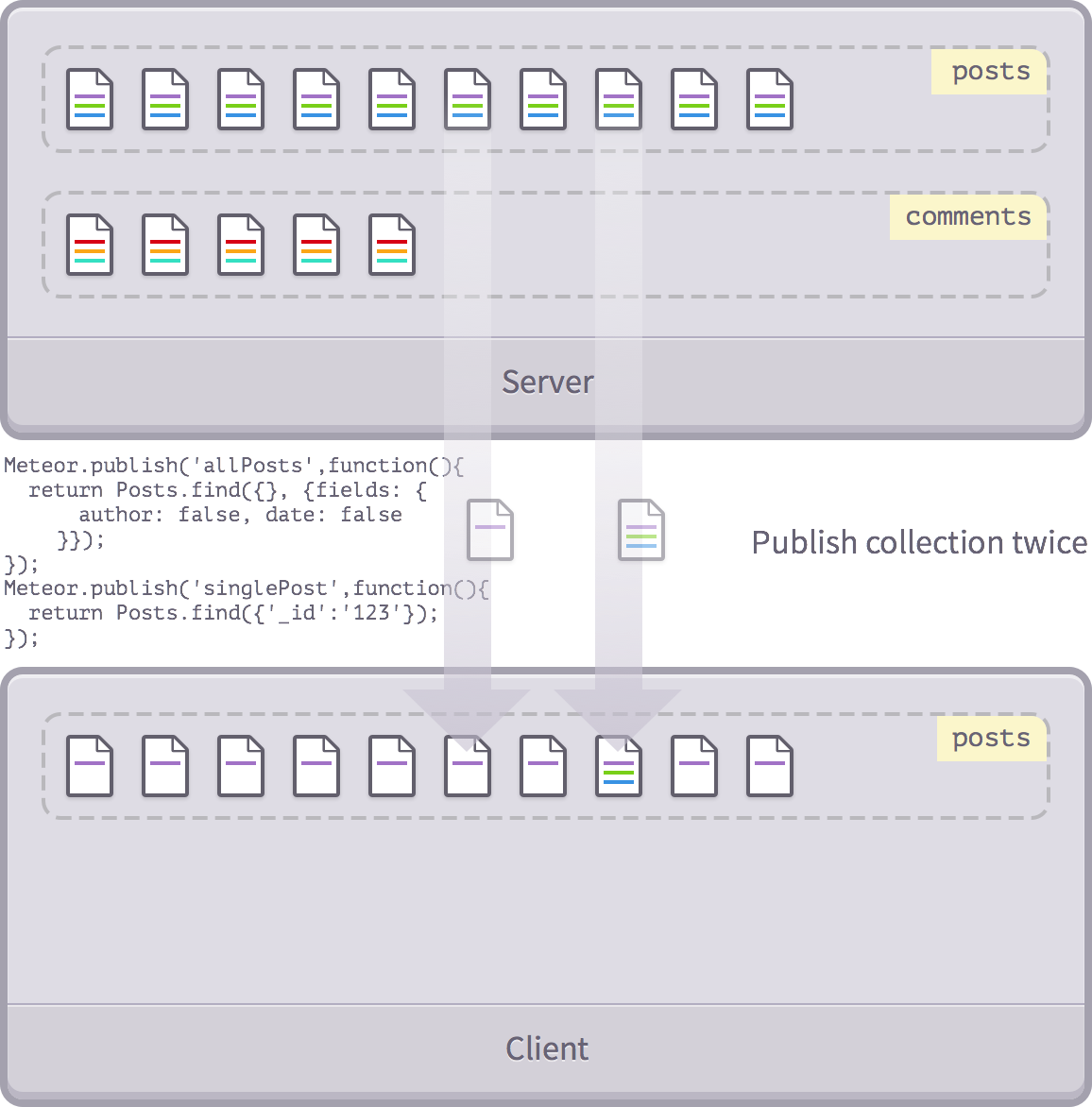
Meteor.publish('allPosts', function() {
return Posts.find({}, {fields: {title: true, author: true}});
});
Meteor.publish('postDetail', function(postId) {
return Posts.find(postId);
});
Now that the client subscribes to both
'posts'
a list of titles and author names from the first subscription, and all information about a single post from the second subscription.
You may be aware that
postDetail
are also
allPosts
only some of its properties are property).
However, Meteor merges fields and confirms that there are no duplicate posts to handle data overlap.
That's great, because now when we present a summary list of posts, the data objects we're working on have just enough data that we need to display. B ut when we present a single post, we have everything we need to present. Of course, in this case, we need to let the client not expect all the fields of all posts to be displayed———— this is a common problem!
Note that you have not changed any restrictions on document properties. You can publish the same properties well in both publications, but sort them differently.
Meteor.publish('newPosts', function(limit) {
return Posts.find({}, {sort: {submitted: -1}, limit: limit});
});
Meteor.publish('bestPosts', function(limit) {
return Posts.find({}, {sort: {votes: -1, submitted: -1}, limit: limit});
});Subscribe to one publication multiple times
We've seen how to publish the same collection multiple times. It turns out that you can do very similar things with another pattern: create a single publication and subscribe to it multiple times.
In Microscope, we repeatedly subscribe to
posts
times, but Iron Router sets up and splits each subscription for us.
However, there is no reason why we
can't subscribe multiple times
at the same time.
For example, we want to load the latest and best posts into memory at the same time:
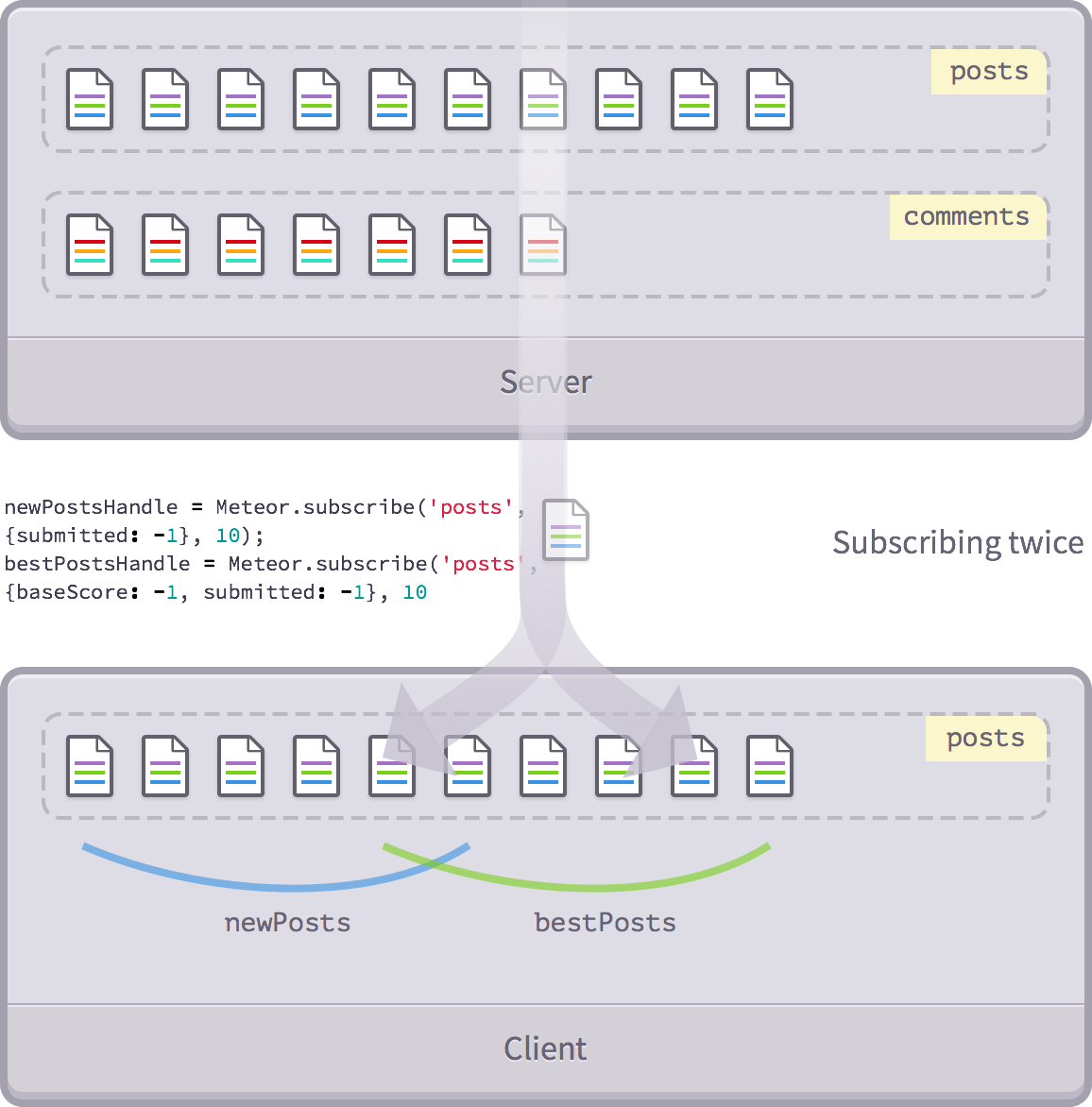
We set a single release:
Meteor.publish('posts', function(options) {
return Posts.find({}, options);
});And we subscribe to this publication many times. In fact, we do this more or less in Microscope:
Meteor.subscribe('posts', {submitted: -1, limit: 10});
Meteor.subscribe('posts', {baseScore: -1, submitted: -1, limit: 10});What's going on next? Each browser opens two different subscriptions, each connected to a publication on the same server.
Each subscription provides different publishing parameters, but fundamentally, one (different) subset of documents at a
posts
collection and sent to the client collection through a connection mechanism.
You can even subscribe to the same publication twice with the same parameters. This is difficult to say useful for many scenarios, but this elastic mechanism will one day be useful.
Multiple collections in a single subscription
Unlike traditional relational databases like MySQL using joins, NoSQL databases like Mongo are all about denormalization and embedding. Let's see how they work in a Meteor environment.
Let's look at a concrete example. We've added comments to our posts, and so far we've been happy to post comments on only individual posts that people see.
However, suppose we want to show replies to all posts on the home page (remember that these posts change when you peddle). This use case shows a good reason to embed comments in a post, which in fact prompts us to denormalize the number of comments.
Of course, we can always embed comments into posts and completely eliminate
Comments
collection.
But as we saw earlier
in the Denormalization
section, we will also lose some additional benefits in the operation of the detached collection.
But it turns out that there's a subscription-related trick to embed our reviews while keeping the collection separate.
Let's assume that in addition to the first page post list, we want to subscribe to two more recent comments for each post.
Using a stand-alone comment post can be difficult to accomplish, especially if the list of posts is subject to certain restrictions (for example, the last 10). We have to write a release that looks like the following code:
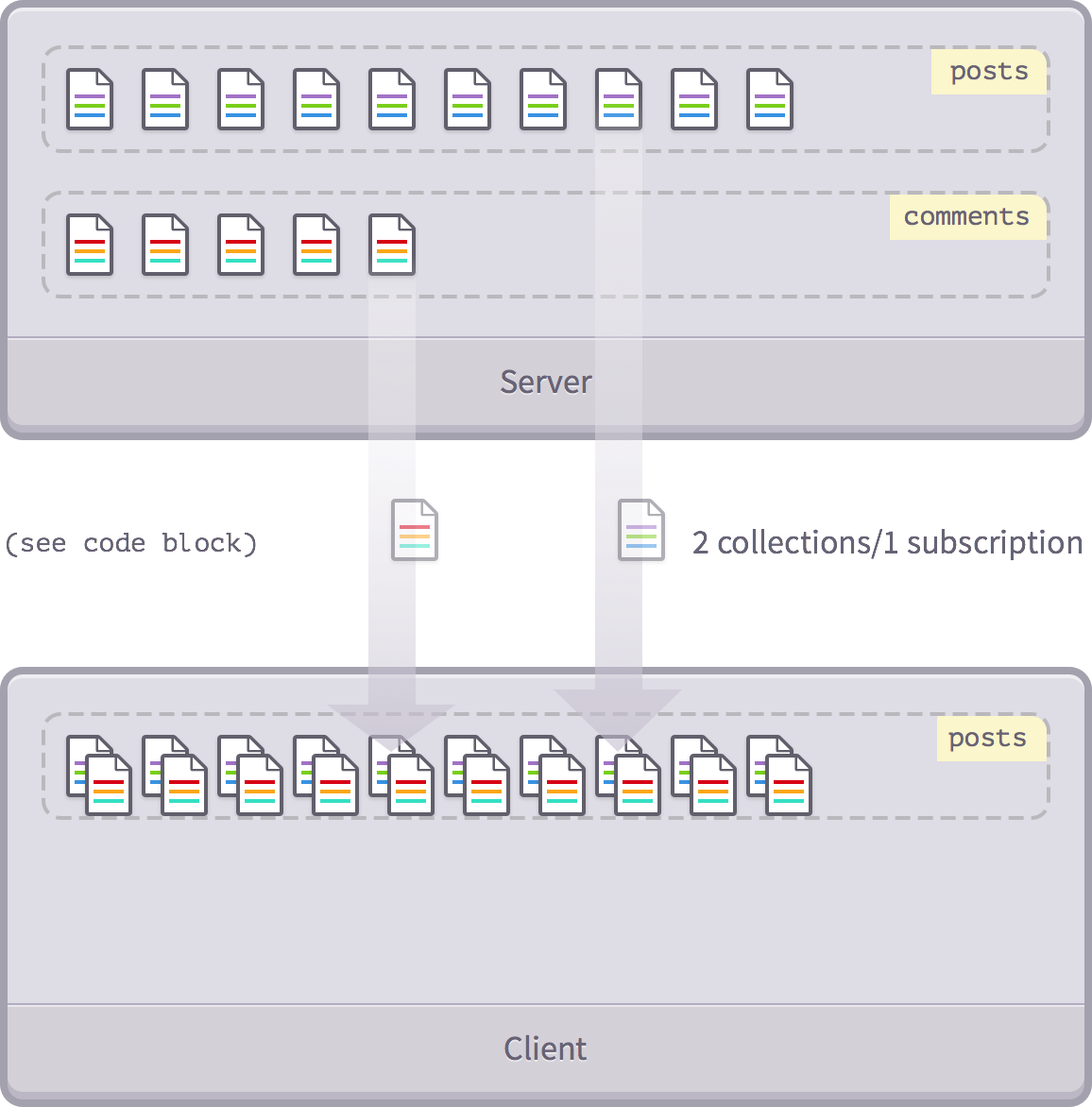
Meteor.publish('topComments', function(topPostIds) {
return Comments.find({postId: topPostIds});
});
This is a problem from a performance perspective because this release will need to be
topPostIds
change.
There is a way to solve this problem. We can apply the fact that not only can we have multiple publications on each collection, but we can also have multiple collections on each publication.
Meteor.publish('topPosts', function(limit) {
var sub = this, commentHandles = [], postHandle = null;
// send over the top two comments attached to a single post
function publishPostComments(postId) {
var commentsCursor = Comments.find({postId: postId}, {limit: 2});
commentHandles[postId] =
Mongo.Collection._publishCursor(commentsCursor, sub, 'comments');
}
postHandle = Posts.find({}, {limit: limit}).observeChanges({
added: function(id, post) {
publishPostComments(id);
sub.added('posts', id, post);
},
changed: function(id, fields) {
sub.changed('posts', id, fields);
},
removed: function(id) {
// stop observing changes on the post's comments
commentHandles[id] && commentHandles[id].stop();
// delete the post
sub.removed('posts', id);
}
});
sub.ready();
// make sure we clean everything up (note `_publishCursor`
// does this for us with the comment observers)
sub.onStop(function() { postHandle.stop(); });
});
Note that we didn't return anything in this release because we manually
sub
(via
.added()
on).
So we don't have to ask for a
_publishCursor
to do this for us.
Now, every time we post a post, we automatically post two of its latest comments. And it's all in one subscription call!
Although Meteor hasn't implemented this approach directly, you can also refer
publish-with-relations
Atomsphere, which aims to make the pattern easier to use.
Connect different collections
Can this subscription elasticity give us more new knowledge?
Of course, if we
_publishCursor
we don't have to follow this constraint, which is that the source collection on the service side needs to have the same name as the client's target collection.
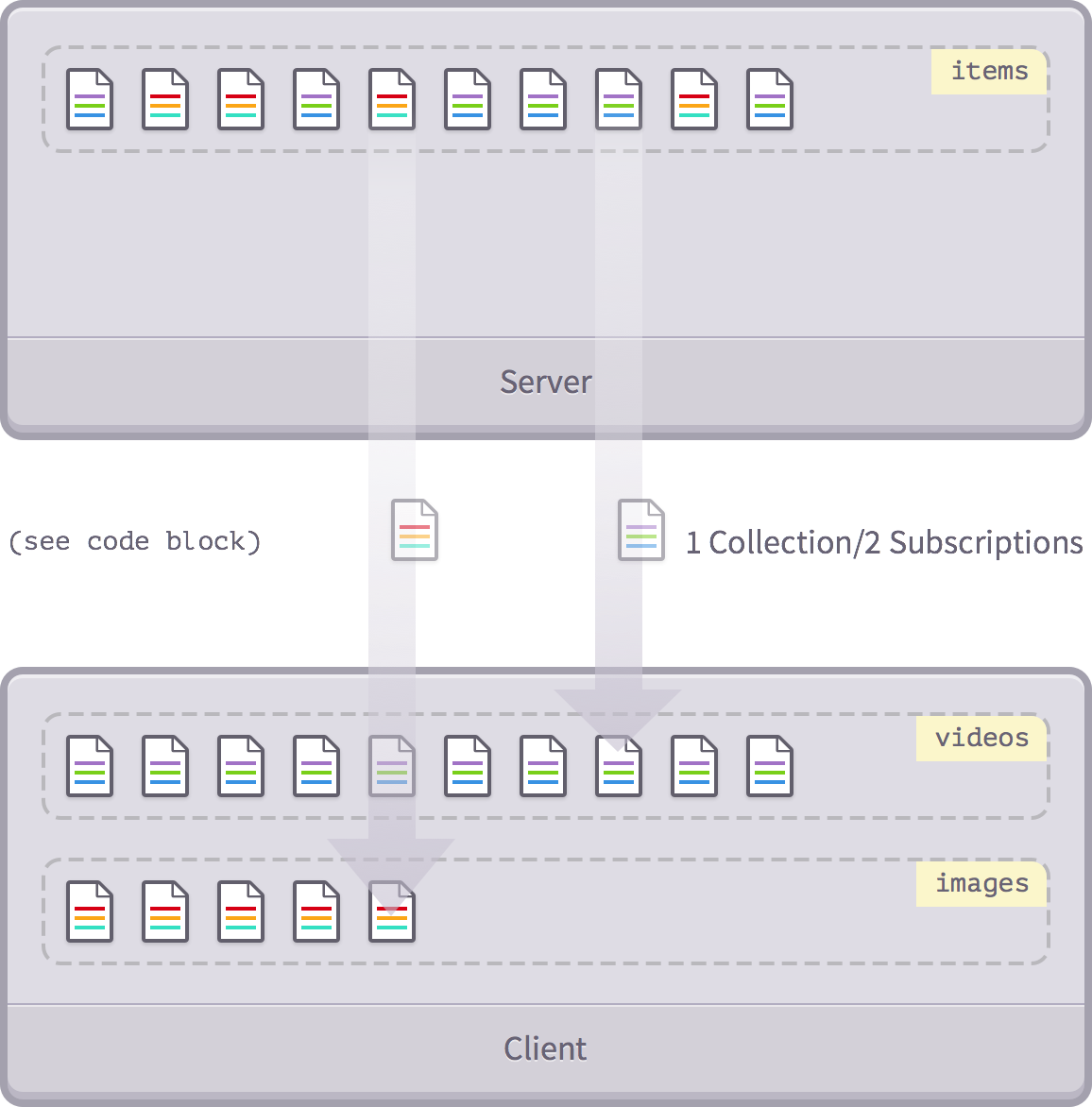
One reason why we want to do this is single-table inheritance.
Suppose we need to reference multiple types of objects from our posts, each stored in the same field but clearly different. For example, let's build a Tumblr-like blog engine, where each post has a common ID, timestamp, and title;
We can store these objects in a separate
'resources'
collection and use
type
to mark what type of
video
image
link
so on).
At the same time, although we have a single
Resources
we are also able to convert a single collection into multiple Collections of
Videos
'Images', and so on.
The collection of clients is as follows:
Meteor.publish('videos', function() {
var sub = this;
var videosCursor = Resources.find({type: 'video'});
Mongo.Collection._publishCursor(videosCursor, sub, 'videos');
// _publishCursor doesn't call this for us in case we do this more than once.
sub.ready();
});
We tell
_publishCursor
(just like back) that the cursor will publish our video
resources
resources
videos
Another similar idea is to publish to a collection of clients without a collection on the server side at all! For example, you might crawl data from a third-party service and publish it to a collection of clients.
Because of the flexibility of publishing APIs, the possibilities are limitless.