Git branch policy
May 25, 2021 Git
Table of contents
Git branch policy
This article will show me the development model I successfully used in my project a year ago. I always intended to write these things, but I never took the time, and now I'm finally done. This is not about the details of any project, but about the policy of the branch and the management of the release.
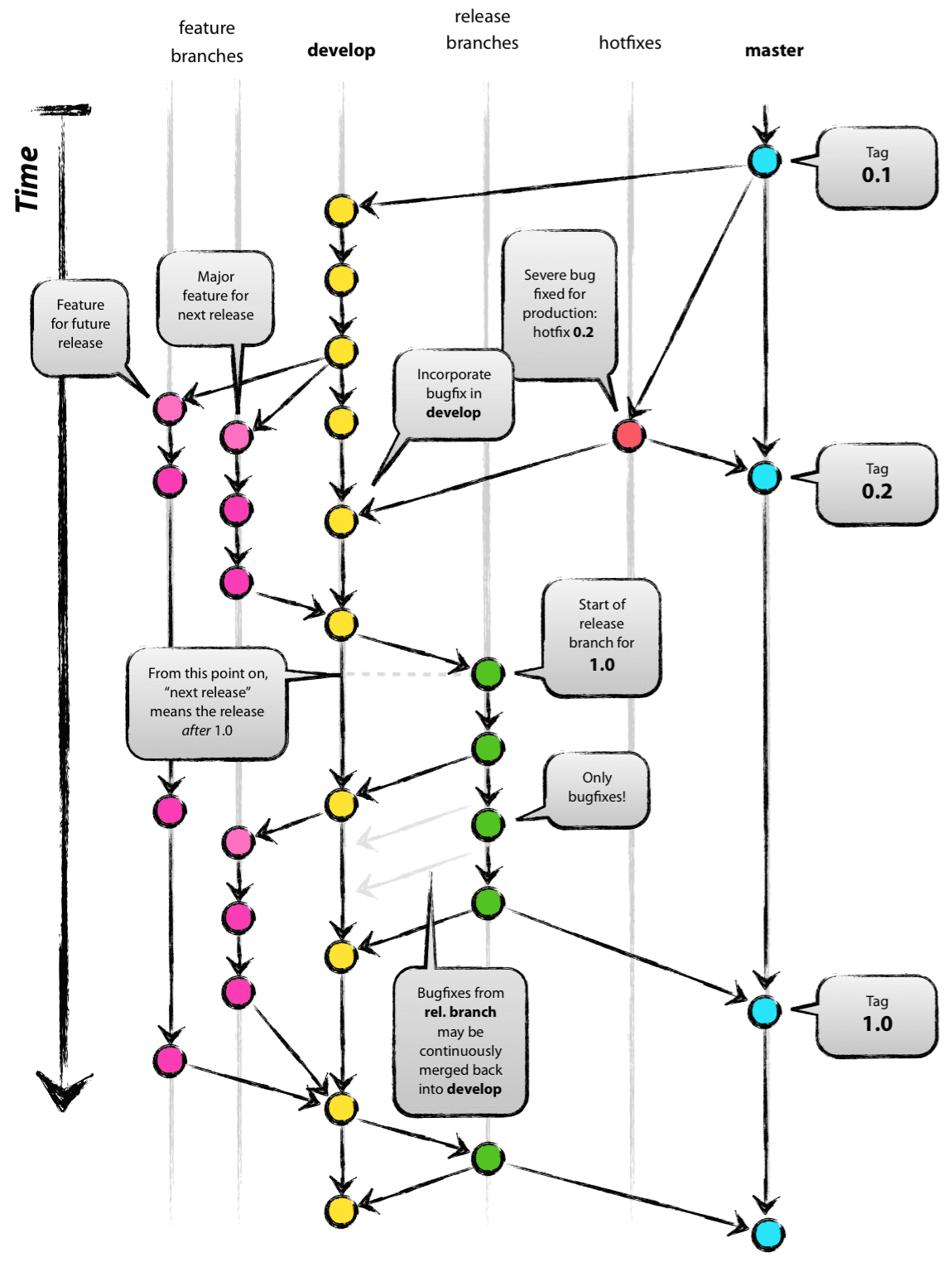
In my demo, everything was done with git.
Why git?
To break the comparison and debate between git and the central source control system, move here to see Link 1 Link 2. A s a developer, I like git more than any other existing tool. G it has really changed the way developers think about merges and branches. In traditional CVS/SVN, merges/branches are always a bit scary ("Watch out for merge conflicts, they kill you").
But these actions in git are so simple and effective that they really are part of your daily workflow. For example, in CVS/SVN books, branching and merging are always the focus of discussion in the last chapter (for advanced users), while in each git book Link 1 Link 2 Link 3, which is already included in Chapter 3 (Basics).
Because of its simplicity, directness and repeatability, branching and merging are no longer scary. Version control tools support branching/merge more than anything else.
That's where the tools are introduced, and we're now getting to the point where we're developing the model. The model I'm presenting is essentially a collection of processes that every team member needs to follow to manage the software development process.
Dispersed but also concentrated
Our branching model uses a good code base to be set up around a real central code base. N ote that the code base here is seen only as a central code base (because git is DVCS, a decentralized version control system that, technically, is not called a central code base). We're used to naming this central code base Origin, which is also the habit of all git users.
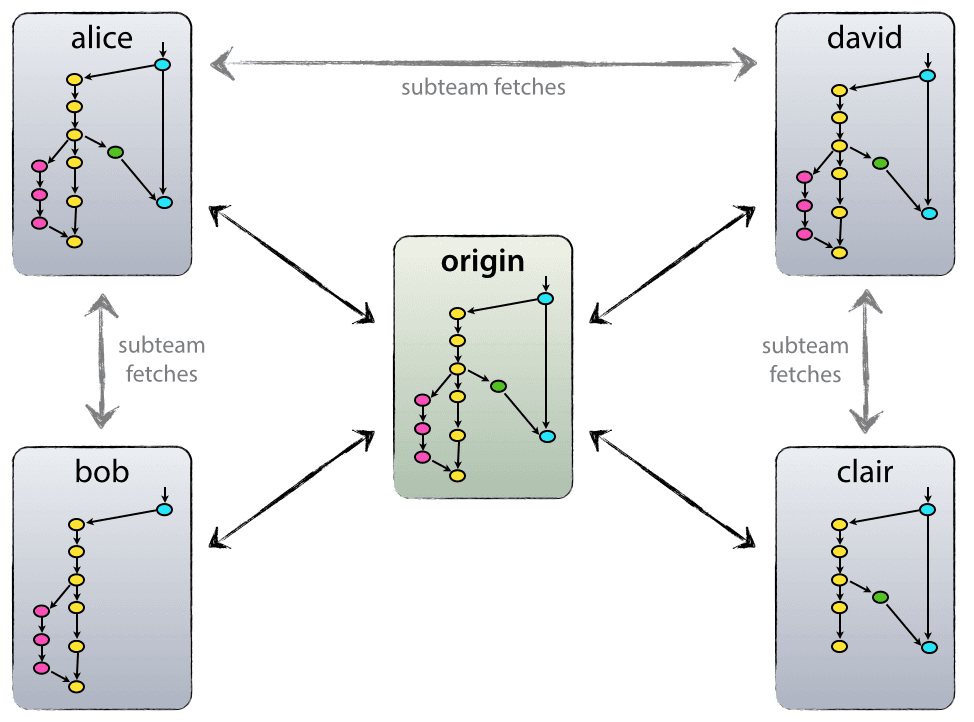
Each developer nodes pull and push to the origin center. B ut beyond that, each developer can change to other node pulls to form sub-teams. F or example, this is useful for more than two developers to develop a large new feature at the same time, so that you don't have to push the development progress to origin too early. In the example above, Alice and Bob, Alice and David, Claire, and David are all sub-teams.
Technically, this means that Alice defines a git remote named Bob, points to Bob's code base, and vice versa.
The main branch
The core of the development model is basically the same as the existing model. The central code base always maintains two main branches:
- master
- develop
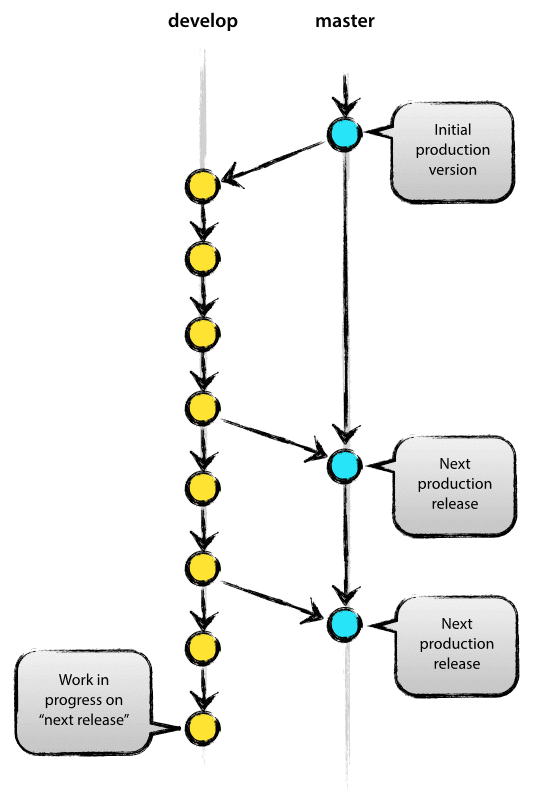
The master branch on origin is consistent with each git user. Another branch that is parallel to the master branch is called develop.
We believe that origin/master is the main branch of its HEAD source code that always represents a state of readiness in the production environment.
We think origin/develop is the main branch whose HEAD source code always represents the last delivery that can catch up with the state of the next release. S ome people also call it an "integrated branch." The source code is also used as a source for nightly build automation tasks.
Whenever the develop branch reaches a stable stage and can be released to the public, all changes are merged into the master branch and a release version tag is hit. How to do this is discussed later.
So every time a change is merged into master, this is a really new release. We recommend strict controls on this, so theoretically we can hook up a hook script for each master branch commit and automate the build and release of our software to the production environment.
Supported branches
In our development model, followed by master and develop main branches, there are a variety of supported branches. T hey are designed to help team members work in parallel with development tasks such as tracking features, preparing for release, and quickly fixing online issues. Different from the previous main branches, they have a limited life cycle and are eventually removed.
The different types of branches we may use are:
- The feature branch
- Release branch
- Hotfix branch
Each branch has a special purpose and strict rules, such as which branches are their starting branches, which branches must be the targets of their merge, and so on. Let's go through them quickly.
These "special" branches are technically not any special. T he type of branch depends on how we use them. They are all ordinary and ordinary git branches.
The feature branch
- May be sent from: develop
- Must be merged back: develop
- Branch naming convention: Any name other than master, develop, release-, or hotfix-
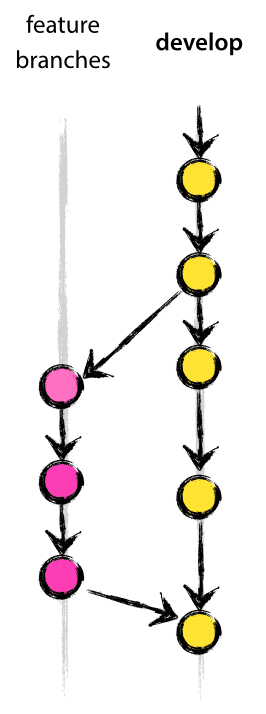
The Feature branch (sometimes referred to as the topic branch) is used to develop new features that include upcoming or forward releases. W hen we started developing a feature, the goal of publishing a merge might not be certain. The lifecycle of the Feature branch is kept in sync with the development cycle of the new feature, but eventually merges back into the develop (well, bring the new feature with you the next time it's released) or is discarded (it's really a cup attempt).
Feature branches typically exist only in the developer's code base and not in origin.
Create a feature branch
When a new feature is started, a branch is issued from the develop branch
$ git checkout -b myfeature develop
Switched to a new branch "myfeature"
Merge the finished attributes back into the develop
The completed features can be merged back into the develop branch and catch up with the next release:
$ git checkout develop
Switched to a new branch "develop"
$ git merge --no-ff myfeature
Updating ea1b82a..05e9557
(Summary of changes)
$ git branch -d myfeature
Deleted branch myfeature (was 05e9557)
$ git push origin develop
The -no-ff tag makes the merge operation always produce a new commit, even if the merge operation can be completed quickly. T his tag avoids mixing historical information about all commits between the feature branch and team collaboration with other commits in the main branch. Compare:
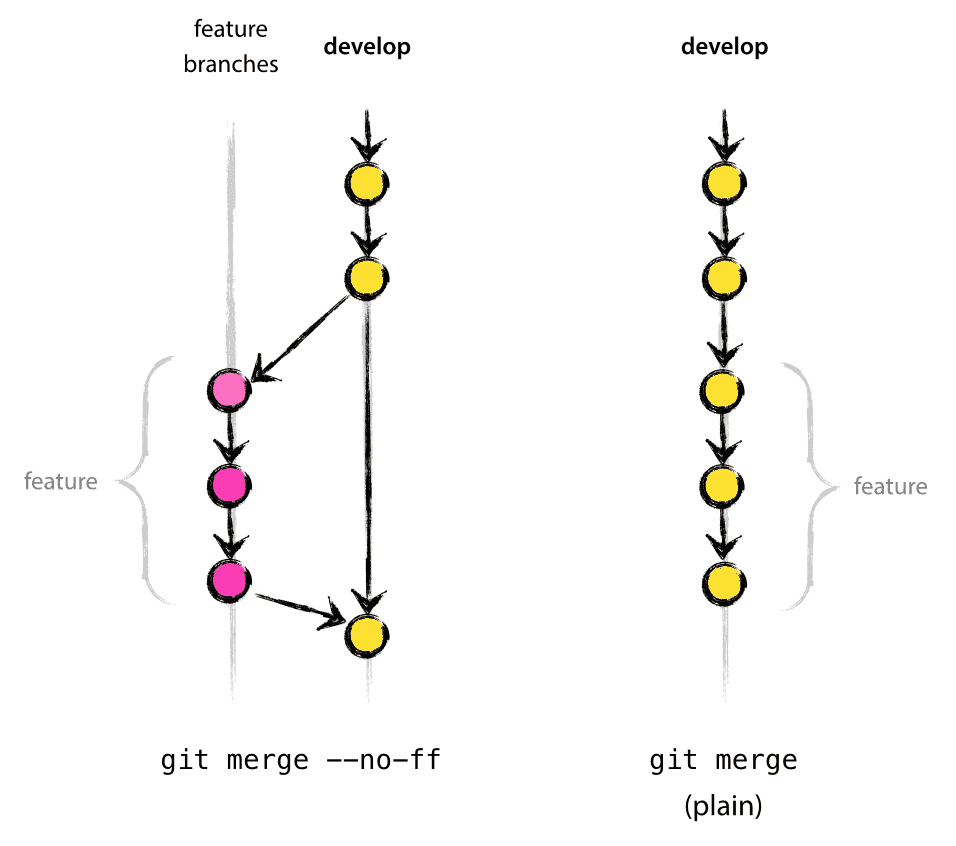
In the example on the right, it's impossible to see from git's history which commits implement this feature -- you might have to look at each commit log. Restoring a complete feature (such as through a set of commits) becomes a headache on the right, and when you use --no-ff, it's easier.
Yes, this creates some unnecessary (empty) commit records, but there are a number of benefits.
Unfortunately, I haven't found a way to mark the --no-ff tag by default at git merge, but that's important.
Release branch
- May be sent from: develop
- Must be merged back: develop and master
- Branch Naming Convention: release-
Release branches are used to support preparation for the release of new production environments. A llows submission points (dotting i's) and junctions (crossing t's) to be generated in the final stages. I t also allows for small problem fixes and meta data when ready for release (e.g. version number, release date, etc.). After the release branch does all of this, the develop branch is "turned over" and begins to receive new features for the next release.
We chose (nearly) to complete all expected development as the time to issue a release branch from the develop faction. A t the very least, all the features that are ready to build a release have been incorporated into the develop branch in a timely manner. Features that are not released later should not be merged into the develop branch -- they must wait until the release branch is sent out before merging.
At the beginning of a release branch, we give it a clear version number. U ntil the branch was created, the description on the develop branch was a change to the "next" release, but the "next" release didn't actually say whether it was 0.3 release or 1.0 release. T his is determined at the beginning of a release branch. This will serve as a code for promotion of project version numbers.
Create a release branch
The Release branch is derived from the develop branch. F or example, our current production environment release is 1.1.5, and there is a release to release right away. T he develop branch is ready for the "next" release, and we have decided to set the new version number to 1.2 (instead of 1.1.6 or 2.0). So we sent out a release branch and named it after the new version number:
$ git checkout -b release-1.2 develop
Switched to a new branch "release-1.2"
$ ./bump-version.sh 1.2
Files modified successfully, version bumped to 1.2.
$ git commit -a -m "Bumped version number to 1.2"
[release-1.2 74d9424] Bumped version number to 1.2
1 files changed, 1 insertions(+), 1 deletions(-)
Once we've created and switched to a new branch, we've completed our promotion to the version number. T he bump-version.sh here is a fictitious shell script that changes some files in the code base to reflect the new version. (Of course you can do these changes manually - the point is that some files have changed) and then the promoted version number will be submitted.
This new branch will exist for some time until it is actually released. T here may be bug fixes during this period (which makes more sense than doing in develop). However, we strictly prohibit the development of large new features here, which should be merged into the develop branch and put into the next release.
Complete a release branch
When the release branch is actually published successfully, there are still things that need to be closed. First, the release branch is merged into the master (don't forget, every commit on the master represents a real new release);
The first two do this under git:
$ git checkout master
Switched to branch 'master'
$ git merge --no-ff release-1.2
Merge made by recursive
(Summary of changes)
$ git tag -a 1.2
Now that the release is complete, the tag is ready for reference in the future.
Added: You can also tag with the -s or -u-lt;key-gt; tag.
In order to keep a record of the changes in the release branch, we need to merge those changes back into the develop. The git operation is as follows:
$ git checkout develop
Switched to branch 'develop'
$ git merge --no-ff release-1.2
Merge made by recursive.
(Summary of changes)
This step has the potential to lead to conflicts (there is only a theoretical possibility that we have changed the version number), once found, resolve the conflict and then commit.
Now that we've actually completed a release branch, it's time to delete it, because its mission is done:
$ git branch -d release-1.2
Deleted branch release-1.2 (was ff452fe).
Hotfix branch
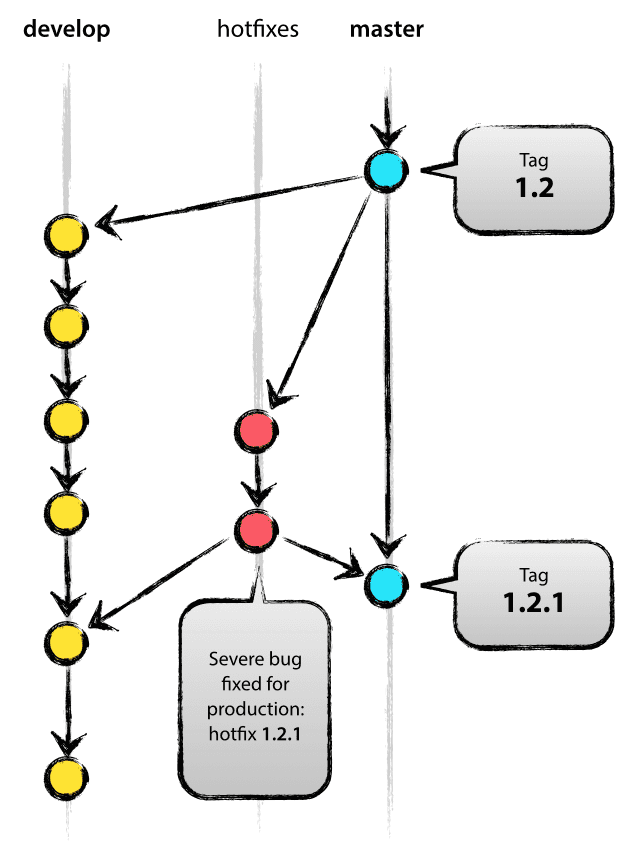
- Probably from: master
- Must be merged back: develop and master
- Branch Naming Convention: hotfix
The Hotfix branch and the release branch are very similar because they both mean a release that will result in a new production environment, although the Hotfix branch is not previously planned. They are sent from the master branch when an unexpected need for a quick response occurs in the real-time production environment version.
The root cause of this is to allow one member of the team to quickly fix problems in the production environment, and the other members to continue working on a work schedule without too much impact.
Create a hotfix branch
Hotfix branches are created from master branches. F or example, suppose version 1.2 is in the current production environment and a serious bug has occurred, but the current develop is not stable enough. So we can send out a hotfix branch to start our repair work:
$ git checkout -b hotfix-1.2.1 master
Switched to a new branch "hotfix-1.2.1"
$ ./bump-version.sh 1.2.1
Files modified successfully, version bumped to 1.2.1.
$ git commit -a -m "Bumped version number to 1.2.1"
[hotfix-1.2.1 41e61bb] Bumped version number to 1.2.1
1 files changed, 1 insertions(+), 1 deletions(-)
Don't forget to promote the version number after sending out a branch!
Then, fix the bug and commit the changes. You can do it with one or more commits.
$ git commit -m "Fixed severe production problem"
[hotfix-1.2.1 abbe5d6] Fixed severe production problem
5 files changed, 32 insertions(+), 17 deletions(-)
Complete a hotfix branch
When we're done, the fix to the bug needs to be merged back to master, and it needs to be merged back to the develop to make sure that the bug has been resolved for the next release. This is exactly the same as how the release branch is done.
First, update master and tag this release:
$ git checkout master
Switched to branch 'master'
$ git merge --no-ff hotfix-1.2.1
Merge made by recursive
(Summary of changes)
$ git tag -a 1.2.1
Added: You can also tag with the -s or -u-lt;key-gt; tag.
Then, merge the fixed bugs into the develop:
$ git checkout develop
Switched to branch 'develop'
$ git merge --no-ff hotfix-1.2.1
Merge made by recursive
(Summary of changes)
An additional feature of this rule is that if a release branch already exists at this point, then the change in hotfix needs to be merged into that release branch, not the develop branch. B ecause after the bug fix is merged back into the release branch, the release branch is eventually merged back into the develop branch. (If you need to fix the bug immediately in the develop branch, and you can't wait for the release branch to merge back, you can still merge it directly back into the develop branch, which is absolutely no problem)
Finally, delete this temporary branch:
$ git branch -d hotfix-1.2.1
Deleted branch hotfix-1.2.1 (was abbe5d6).
Summary
In fact, there is nothing new in this branch model. T he big picture at the beginning of the article is very useful for our project. It is very easy for team members to understand this elegant and effective model and reach consensus within the team.
There's also a high-definition PDF version of that big picture, which you can use as a manual to take a quick look at.
Added: Also, there's a Keynote version here if you need it
This article is translated from: A successful Git branching model nvie.com