Cassandra data model
May 17, 2021 Cassandra
Table of contents
Cassandra's data model is very different from the one we typically see in RDBMS. /b10> This chapter provides an overview of how Cassandra stores data.
Cluster
Cassandra databases are distributed across several machines that operate together. /b20> The outer outerst container is called a cluster. b20> For troubleshooting, each node contains a copy that, in the event of a failure, is replicated. /b20> Cassandra arranges nodes in a cluster in a circular format and assigns data to them.
Key space
(Keyspace)
Keyspace is the outermost container of data in Cassandra. The basic property of a keyspace in Cassandra is -
-
Replication Factor - It is the number of computers in the cluster that will receive copies of the same data.
-
Replica placement policy - It's just a policy to put a copy on media. /b20> We have simple policies (rack-aware policies), old network topology policies (rack-aware policies), and network topology policies (data center sharing policies).
-
Column family - The keyspace is a container for a list of one or more column familyes. /b20> A column family is also a container for a collection of rows. /b21> Each row contains a sequence. /b22> Column familyes represent the structure of the data. /b23> Each key space has at least one, usually many column families.
The syntax for creating a key space is as follows -
CREATE KEYSPACE Keyspace name
WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};
The following illustration shows a diagram of the key space.
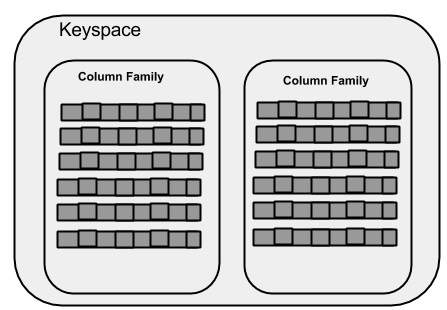
Column family
A column family is a container for an ordered collection of rows. /b20> Each row is an ordered collection of columns. /b20> The following table lists the key points for distinguishing column series from relationship database tables.
| The relationship table | Cassandra column family |
|---|---|
|
Patterns in the relationship model are fixed.
/b10>
Once some columns are defined for a table, all columns must be filled with at least one empty value in each row when data is inserted.
|
In Cassandra, although column familyes are defined, columns are not. /b10> You can freely add any column to any column family at any time. |
| The relationship table defines only columns, and the user populates the table with values. | In Cassandra, a table contains columns, or can be defined as a super-column family. |
Cassandra column family has the following properties -
-
keys_cached - It represents the number of locations where each SSTable remains cached.
-
rows_cached - The number of rows whose entire contents will be cached in memory.
-
preload_row_cache - It specifies whether you want to prefill the row cache.
Note - Unlike the relationship table for patterns that are not fixed column familyes, Cassandra does not force a single row to own all columns.
The following illustration shows an example of a Cassandra column family.
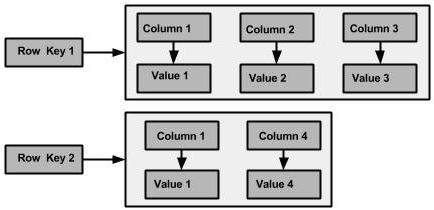
Column

Super column
The super column is a special column, so it is also a key value pair. /b10> But the super column stores the map of the child column.
Typically, column familyes are stored in a single file on disk. /b20> Therefore, in order to optimize performance, it is important to keep the columns that you might query together in the same column family, and super columns can be helpful here. H ere's the structure of the super column.

Cassandra and RDBMS data models
The following table lists the key points for distinguishing between Cassandra's data model and RDBMS's data model.
| Rdbms | Cassandra |
|---|---|
| RDBMS processes structured data. | Cassandra processes unstructured data. |
| It has a fixed pattern. | Cassandra has a flexible architecture. |
| In RDBMS, a table is an array of arrays. ( ROW x COLUMN ) | In Cassandra, the table is a list of nested key value pairs. (ROW x COLUMN key x COLUMN value). |
| A database is the outermost container that contains data that corresponds to the application. | Keyspace is the outermost container that contains the data that corresponds to the application. |
| The table is the entity of the database. | A table or column family is an entity of key space. |
| Row is a single record in RDBMS. | Row is a replication unit in Cassandra. |
| The column represents the properties of the relationship. | Column is the storage unit in Cassandra. |
| RDBMS supports the concept of foreign keys, connections. | Relationships are represented by collections. |