Apache Pig architecture
May 26, 2021 Apache Pig
Table of contents
The language used to analyze data in Hadoop, called Pig Latin, is an advanced data processing language that provides a rich set of data types and operators to perform a variety of operations on the data.
To perform specific tasks, programmers use Pig, which needs to be scripted in the Pig Latin language and executed using any execution mechanism (Grunt Shell, UDFs, Embedded). /b10> Once executed, these scripts generate the desired output by applying a series of transformations to the Pig framework.
Internally, Apache Pig converts these scripts into a series of MapReduce jobs, making it easy for programmers to work. /b10> Apache Pig's architecture looks like this.
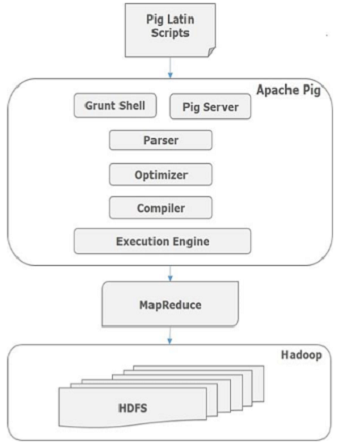
Apache Pig component
As shown in the figure, there are various components in the Apache Pig framework. /b10> Let's take a look at the main components.
Parser (Parser)
Initially, the Pig script is handled by the parser, which checks the syntax of the script, type checking, and other miscellaneous checks. /b11> The output of the parser will be DAG (with a ringless graph), which represents the Pig Latin statement and the logical operator. /b12> In DAG, the logical operator of the script is represented as a node and the data stream is represented as an edge.
Optimizer (optimizer)
The Logic Plan (DAG) is passed to the Logic Optimizer, which performs logical optimizations such as projection and push-down.
Compiler (compiler)
The compiler compiles the optimized logic plan into a series of MapReduce jobs.
Execution engine (execution engine)
Finally, the MapReduce job is submitted to Hadoop in sort order. /b10> These MapReduce jobs are performed on Hadoop to produce the desired results.
Pig Latin data model
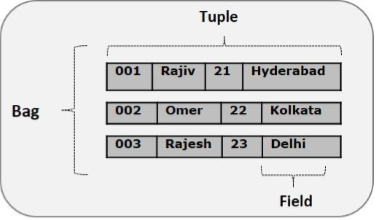
Pig Latin's data model is fully nested and allows complex non-atomic data types such as map and tuple. /b10> A graphical view of the Pig Latin data model is given below.
Atom (Atomic)
Any single value in Pig Latin, regardless of its data type, is called Atom. I t is stored as a string and can be used as a string and number. I nt, long, float, double, chararray and bytearray are the atomic values of Pig. A data or a simple atomic value is called a field. Example: "raja" or "30"
Tuple (Tuple)
Records formed by an ordered collection of fields are called metagroups, and fields can be of any type. /b10> The metagroup is similar to the rows in the RDBMS table. Example: (Raja, 30).
Bag (Bag)
A package is a disordered set of metagroups. /b10> In other words, a collection of metagroups (not unique) is called a package. /b11> Each group can have any number of fields (flexible mode). /b12> The package is represented by a """ /b13> It is similar to a table in RDBMS, but unlike a table in RDBMS, you do not need each group to contain the same number of fields, or to have the same type of field in the same location (column).
Example: (Raja, 30), (Mohammad, 45)
A package can be a field in a relationship;
Example: .Raja, 30, .9848022338,[email protected], . . }
Map (Map)
A map (or data map) is a set of key-value pairs. Key needs to be acharray type and should be unique. Value can be any type, it can be represented by the """"
Example: .name#Raja, age#30
Relation (Relationship)
A relationship is a package of meta-groups. /b10> The relationships in Pig Latin are out of order (there is no guarantee that the DTs will be processed in any particular order).