Apache Kafka's integration with Spark
May 26, 2021 Apache Kafka
Table of contents
In this chapter, we'll discuss how to integrate Apache Kafka with the Spark Streaming API.
About Spark
The Spark Streaming API supports scalable, high throughput, and fault-02 flow processing for real-time data streams. /b10> Data can be extracted from many sources such as Kafka, Flume, Twitter, and can be processed using sophisticated algorithms such as maps, zoom-outs, connections, and windows. /b11> Finally, the processed data can be pushed to file systems, databases, and active dashboards. /b12> Elastic Distributed Data Set (RDD) is the basic data structure of Spark. /b13> It is an immedible collection of distributed objects. /b14> Each dataset in the RDD is divided into logical partitions that can be calculated on different nodes of the cluster.
Integration with Spark
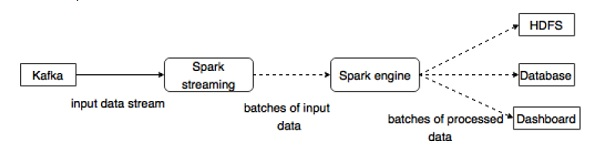
Kafka is a potential messaging and integration platform for Spark streaming. /b10> Kafka acts as a hub for real-time data streaming and is processed using complex algorithms in Spark Streaming. /b11> Once the data is processed, Spark Streaming can publish the results to another Kafka theme or store them in a PDFS, database, or dashboard. /b12> The following diagram describes the conceptual process.
Now let's take a look at the Kafka-Spark API.
SparkConf API
It represents the configuration of the Spark application. /b10> Used to set various Spark parameters to key value pairs.
The SparkConf
class has the following methods -
-
set (string key, string value) - set the configuration variable.
-
remove (string key) - Remove the key from the configuration.
-
setAppName (string name) - set the application name of the application.
-
get(string key) - get key
StreamingContext API
This is the main entry point for spark functionality. /b10> SparkContext represents a connection to a Spark cluster that can be used to create RDDs, adders, and broadcast variables on the cluster. /b11> The definition of a signature is shown below.
public StreamingContext(String master, String appName, Duration batchDuration, String sparkHome, scala.collection.Seq<String> jars, scala.collection.Map<String,String> environment)
-
Main - Cluster URL to connect to (e.g mesos:// host:port, spark: host:port, local .
-
AppName - The name of the job to display on the cluster Web UI
-
batchDuration - Streaming data is divided into batches at intervals
public StreamingContext(SparkConf conf, Duration batchDuration)
Create StreamingContext by providing the configuration required for the new SparkContext.
-
conf - Spark parameters
-
batchDuration - Streaming data is divided into batches at intervals
KafkaUtils API
The Kafka Utils API is used to connect Kafka clusters to Spark streams.
/b10>
This API has a significant method,
createStream, as defined below.
public static ReceiverInputDStream<scala.Tuple2<String,String>> createStream( StreamingContext ssc, String zkQuorum, String groupId, scala.collection.immutable.Map<String,Object> topics, StorageLevel storageLevel)
The method shown above is used to create an input stream that extracts messages from Kafka Brokers.
-
ssc - StreamingContext object.
-
zkQuorum - Zookeeper quorum。
-
GroupId - The group ID of this consumer.
-
Themes - Returns a map of the topics you want to consume.
-
StorageLevel - The level of storage used to store received objects.
The KafkaUtils API has another way to create an input stream that pulls messages directly from Kafka Brokers without using any receivers. /b10> This flow ensures that every message from Kafka is included once in the transformation.
The sample application is done in Scala.
/b10>
To compile the application, download and install
the sbt,
scala build tool (similar to maven).
/b11>
The main application code is shown below.
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, Produc-erRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
object KafkaWordCount {
def main(args: Array[String]) {
if (args.length < 4) {
System.err.println("Usage: KafkaWordCount <zkQuorum><group> <topics> <numThreads>")
System.exit(1)
}
val Array(zkQuorum, group, topics, numThreads) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
ssc.checkpoint("checkpoint")
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L))
.reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
Build the script
Spark-kafka integration depends on Spark, Spark Stream and Spark's integration jar with Kafka.
/b10>
Create a new file
build.sbt and
specify the application details and their dependencies.
/b11>
When the application is compiled and packaged,
sbt
downloads the required jar.
name := "Spark Kafka Project" version := "1.0" scalaVersion := "2.10.5" libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.0" libraryDependencies += "org.apache.spark" %% "spark-streaming" % "1.6.0" libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka" % "1.6.0"
Compilation/packaging
Run the following commands to compile and package the application's jar files. /b10> We need to submit the jar file to the spark console to run the application.
sbt package
Submit to Spark
Start the Kafka Producer CLI (explained in the previous chapter), create a
new topic called my-first-topic,
and provide some sample messages, as shown below.
Another spark test message
Run the following command to submit the application to the spark console.
/usr/local/spark/bin/spark-submit --packages org.apache.spark:spark-streaming -kafka_2.10:1.6.0 --class "KafkaWordCount" --master local[4] target/scala-2.10/spark -kafka-project_2.10-1.0.jar localhost:2181 <group name> <topic name> <number of threads>
The sample output for this application is shown below.
spark console messages .. (Test,1) (spark,1) (another,1) (message,1) spark console message ..