Posts about Apache Pig

Apache Pig overview
May 26, 2021 12:00 0 Comment Apache Pig
What is Apache Pig?, What is Apache Pig?, Why do we need Apache Pig?, Apache Pig features, Apache Pig and MapReduce, Apache Pig Vs SQL, Apache Pig VS Hive, Apache Pig app, Apache Pig history, What is Apache Pig?, Apache Pig is an abstraction of MapReduce., /b10>, It is a tool/platform for analyzing large data sets and representing them as d
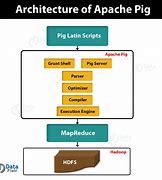
Apache Pig architecture
May 26, 2021 13:00 0 Comment Apache Pig
Apache Pig component, Apache Pig component, Pig Latin data model, The language used to analyze data in Hadoop,, called Pig Latin,, is an advanced data processing language that provides a rich set of data types, and o
Apache Pig installation
May 26, 2021 13:00 0 Comment Apache Pig
Prerequisite, Prerequisite, Download Apache Pig, Install Apache Pig, Configure Apache Pig, This chapter describes how to download, install, and set up, Apache Pig in your system., Prerequisite, Hadoop and Java must be installed on the system

Apache Pig performs
May 26, 2021 13:00 0 Comment Apache Pig
Apache Pig execution mode, Apache Pig execution mode, Apache Pig execution mechanism, Call the Grunt shell, Perform Apache Pig in batch mode, In the last chapter, we explained how to install Apache Pig., /b10>, In this chapter, we'll discuss how to execute Apache Pig., Apache Pig execution m

Apache Pig Grunt Shell
May 26, 2021 13:00 0 Comment Apache Pig
Shell command, Shell command, Utility commands, After calling the Grunt shell, you can run the Pig script in the shell., /b10>, In addition, there are some useful shell and utility commands provided

Pig Latin Foundation
May 26, 2021 13:00 0 Comment Apache Pig
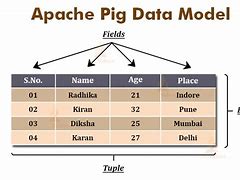
Pig Latin - Data model, Pig Latin - Data model, Pig Latin - Statement, Pig Latin - Data type, Null value, Pig Latin - Arithmetic operator, Pig Latin - Comparison operator, Pig Latin - Type Structure Operator, Pig Latin - Relationship operator, Pig Latin is the language used to analyze data in Hadoop using Apache Pig., In this chapter, we'll discuss the basics of Pig Latin, such as Pig Latin
Apache Pig loads the data
May 26, 2021 13:00 0 Comment Apache Pig
Prepare HDFS, Prepare HDFS, Load operator, In general, Apache Pig works on Hadoop. I, t is an analysis tool for, analyzing large, data sets that exist in, the H, adoop F ile, S, ystem. T, o ana
Apache Pig stores data
May 26, 2021 13:00 0 Comment Apache Pig
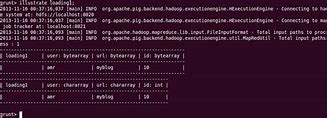
Grammar, Grammar, Cases, Verify, In the last chapter, we learned how to load data into Apache Pig. Y, ou can, use the, Store, operator to store loaded data in the file system, and, th
Apache Pig Diagnostic operator
May 26, 2021 13:00 0 Comment Apache Pig
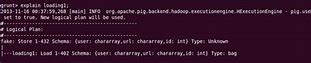
Dump operator, Dump operator, The Load, statement simply loads the data into the specified relationship in Apache Pig., /b10>, To verify the execution of a, Load, statement, you mu
Apache Pig Describe operator
May 26, 2021 13:00 0 Comment Apache Pig
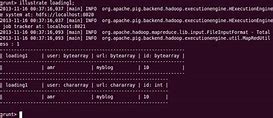
Grammar, Grammar, Cases, Output, The describe, operator is used to view the pattern of the relationship., Grammar, The, syntax of the describe operator is as follows, grunt> Describe
Apache Pig Explain operator
May 26, 2021 13:00 0 Comment Apache Pig
Grammar, Grammar, Cases, Output, The explain, operator is used to display the logic, physics, and MapReduce execution plans for relationships., Grammar, The, syntax of, the explain op

Apache Pig indicator operator
May 26, 2021 14:00 0 Comment Apache Pig
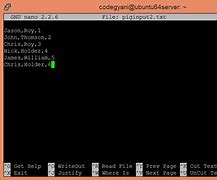
Grammar, Grammar, Cases, Output, The play, operator gives you step-by-step execution of a series of statements., Grammar, The, syntax of, the indicator operator is given below., grunt
Apache Pig Group operator
May 26, 2021 14:00 0 Comment Apache Pig
Grammar, Grammar, Cases, Verify, Output, Group by multiple columns, Group All, The GROUP, operator is used to group data in one or more relationships, and it collects, data with the same key., Grammar, The, syntax of, the group o
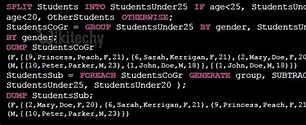
Apache Pig Cogroup operator
May 26, 2021 14:00 0 Comment Apache Pig
Use Cogroup to group two relationships, Use Cogroup to group two relationships, The COGROUP, operator works in the same, way as, the GROUP operator., /b10>, The only difference between the two operators is, that the group operator

Apache Pig Join operator
May 26, 2021 14:00 0 Comment Apache Pig
Self-join (self-connection), Self-join (self-connection), Inner Join (Internal Connection), Left Outer Join (left outer connection), Right Outer Join (right outside connection), Full Outer Join (Full External Connection), Use multiple Keys, The JOIN, operator is used to combine records from two or more relationships., /b10>, When performing a connection operation, we declare one (or a gro