Posts about Apache Kafka
Apache Kafka Overview
May 26, 2021 16:00 0 Comment Apache Kafka
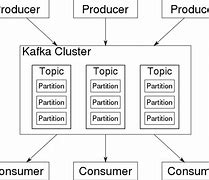
What is a messaging system?, What is a messaging system?, What is Kafka?, In big data, a lot of data is used., /b10>, We have two main challenges with data. T, he first challenge is how to collect large amounts of data, and

Apache Kafka Foundation
May 26, 2021 16:00 0 Comment Apache Kafka
Apache Kafka Foundation, For big data, we have a lot of questions to consider, first how to collect large amounts of data (such as Flume), then how to store the collected data
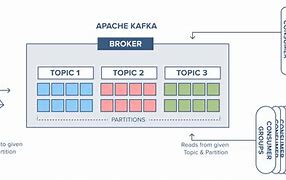
Apache Kafka cluster architecture
May 26, 2021 16:00 0 Comment Apache Kafka
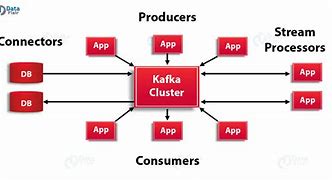
Apache Kafka cluster architecture, Take a look at the illustration below., /b10>, It shows Kafka's cluster diagram., The following table describes each component shown in the figure abo
Apache Kafka workflow
May 26, 2021 16:00 0 Comment Apache Kafka
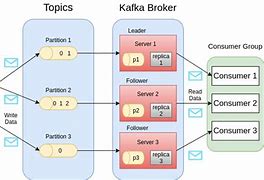
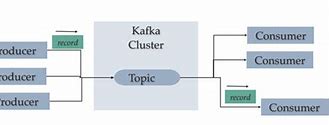
Publish - The workflow for subscribing to messages, Publish - The workflow for subscribing to messages, The workflow for the queue message/user group, ZooKeeper's role, So far, we've discussed kafka's core concepts., Let's take a look at Kafka's workflow now., Kafka is just a collection of topics divided into one or m
Apache Kafka installation steps
May 26, 2021 16:00 0 Comment Apache Kafka
Step 1 - Verify the Java installation, Step 1 - Verify the Java installation, Step 2 - ZooKeeper frame installation, Step 3 - Apache Kafka installation, Step 4 - Stop the server, Here are the steps to install Java on the machine., Step 1 - Verify the Java installation, Hopefully you've installed java on your machine, so you jus
Apache Kafka Basic Operations
May 26, 2021 16:00 0 Comment Apache Kafka
Start ZooKeeper, Start ZooKeeper, 单节点 - 单代理配置, 主题列表, 单节点多代理配置, 创建主题, 基本主题操作, First let's start with, a single-node single-agent, configuration, and then we migrate our settings to a single-node multi-agent configuration., Hopef
Apache Kafka simple producer example
May 26, 2021 16:00 0 Comment Apache Kafka
KafkaProducer API, KafkaProducer API, Producer API, Configure the settings, SimpleProducer application, A simple example of a consumer, ConsumerRecord API, ConsumerRecords API, Configure the settings, SimpleConsumer application, Let's use the Java client to create an application for publishing and using messages., /b10>, The Kafka producer client includes the following APIs.,
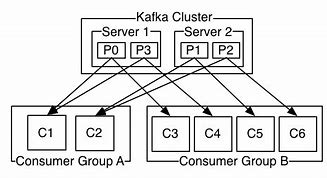
Apache Kafka consumer group example
May 26, 2021 16:00 0 Comment Apache Kafka
Consumer groups, Consumer groups, Consumer groups are multithreaded or multi-machine Apache Kafka themes., Consumer groups, Consumers can join, group.id using, the same information, Th
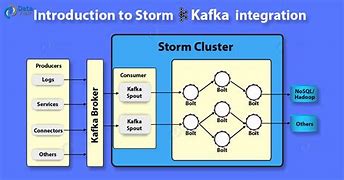
Apache Kafka integrates Storm
May 26, 2021 17:00 0 Comment Apache Kafka
About Storm, About Storm, Integration with Storm, Create Bolt, Submit the topology, In this chapter, we'll learn how to integrate Kafka with Apache Storm., About Storm, Storm was originally created by the team of Nathan Marz and BackT
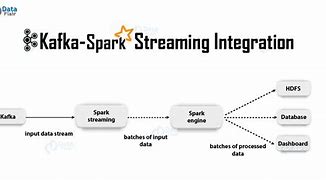
Apache Kafka's integration with Spark
May 26, 2021 17:00 0 Comment Apache Kafka
About Spark, About Spark, Integration with Spark, In this chapter, we'll discuss how to integrate Apache Kafka with the Spark Streaming API., About Spark, The Spark Streaming API supports scalable, hi

Apache Kafka Live App (Twitter)
May 26, 2021 17:00 0 Comment Apache Kafka
Twitter Streaming API, Twitter Streaming API, Let's analyze a real-time app to get the latest Twitter feeds and their tags., /b10>, Earlier, we had seen the integration of Storm and Spark with Kaf
Apache Kafka tool
May 26, 2021 17:00 0 Comment Apache Kafka
System tools, System tools, Copy Tool", Kafka at "org.apache.kafka.tools." ", Under the packaged tool., /b10>, Tools are divided into system tools and replication tools., System tools, You c

Apache Kafka app
May 26, 2021 17:00 0 Comment Apache Kafka
Apache Kafka app, Twitter, Linkedin, Netflix, Mozilla, Oracle, Kafka supports many of today's best industrial applications., /b10>, We'll briefly describe Kafka's most remarkable applications in this chapter., Twi

Apache Kafka Quick Guide
May 26, 2021 17:00 0 Comment Apache Kafka
What is a messaging system?, What is a messaging system?, What is Kafka?, Publish - The workflow for subscribing to messages, The workflow for the queue message/user group, ZooKeeper's role, Step 1 - Verify the Java installation, Step 2 - ZooKeeper frame installation, Step 3 - Apache Kafka installation, Step 4 - Stop the server, Start ZooKeeper, Single-node - single-agent configuration, The list of topics, Single-node multi-agent configuration, Create a theme, Basic topic actions, KafkaProducer API, Producer API, Configure the settings, SimpleProducer application, A simple example of a consumer, ConsumerRecord API, ConsumerRecords API, Configure the settings, SimpleConsumer application, Consumer groups, About Storm, Integration with Storm, Create Bolt, Apache Kafka - Introduction, In big data, a lot of data is used., /b10>, We have two main challenges with data. T, he first challenge is how to collec
Apache Kafka resources
May 26, 2021 17:00 0 Comment Apache Kafka
Apache Kafka related links, Apache Kafka related links, Apache Kafka books, The following resources contain additional information about Apache Kafka., /b10>, Use them for more in-depth knowledge., Apache Kafka related links,