A first look at the Nginx architecture
May 23, 2021 Nginx Getting started
Table of contents
A first look at the Nginx architecture
Nginx is known for its high performance, and Nginx's high performance is insegotable from its architecture. S o what exactly is Nginx like? Let's take a first look at the Nginx framework in this section.
After Nginx is started, it runs in the background as a daemon in the unix system, which contains a master process and multiple worker processes. W e can also manually turn off background mode, let Nginx run in the foreware, and configure Nginx to cancel the master process, which allows Nginx to run as a single process. O bviously, we certainly wouldn't do that in a production environment, so turning off background mode, which is generally used for debugging, will explain in detail how to debug Nginx in a later section. S o, we can see that Nginx works in a multi-process way, and of course Nginx supports a multithreaded approach, but our mainstream approach is a multi-process approach and the default way for Nginx. Nginx has many benefits from a multi-process approach, so let's focus on Nginx's multi-process pattern.
As mentioned earlier, Nginx has a master process and multiple worker processes after it is started. M aster processes are primarily used to manage worker processes, including receiving signals from the outside world, sending signals to each worker process, monitoring the running status of the worker process, and automatically restarting the new worker process when the worker process exits (in exceptional cases). B asic network events, on the other hand, are handled in the worker process. M ultiple worker processes are equivalent to each other, competing equally for requests from clients, and processes are independent of each other. A request can only be processed in one worker process, one worker process, and it is not possible to process requests from other processes. T he number of worker processes can be set, and generally we set them to match the number of machine cpu cores, which are indesoly related to Nginx's process model and event processing model. The process model of Nginx, which can be represented by the following image:
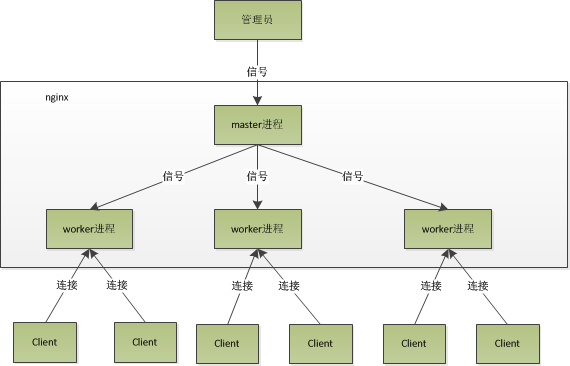
After Nginx starts, what do we do if we're going to operate Nginx? A
s we can see from the above, master manages the worker process, so we just need to communicate with the master process. T
he master process receives signals from the outside world and does different things based on the signals. S
o we're going to control Nginx, just send a signal to the master process through kill.
kill -HUP pid
tells Nginx to restart Nginx calmly, which we typically use to restart Nginx, or to reload the configuration, because it is a calm restart, so the service is non-disruptive. W
hat does the master process do when it receives a HUP signal? F
irst, after receiving the signal, the master process reloads the profile before starting a new worker process and sending a signal to all the old worker processes that they can retire with honor. T
he new worker starts receiving new requests after starting, while the old worker no longer receives new requests when he receives a signal from master, and exits after all outstanding requests in the current process have been processed. O
f course, sending a signal directly to the master process is an older way of doing things, and Nginx introduced a series of command-line parameters after version 0.8 to make it easier for us to manage. F
or example,
./nginx -s reload
which is to restart Nginx,
./nginx -s stop
is to stop Nginx from running. H
How do you do that?
Let's take reload, we see that when we execute the command, we start a new Nginx process, and when the new Nginx process resolves to the reload parameter, we know that our goal is to control Nginx to reload the profile, and it sends a signal to the master process, and then the next action is the same as we send a signal directly to the master process.
Now that we know what we've done inside Nginx while we're operating Nginx, how does the worker process handle requests? A s we mentioned earlier, there is equality between worker processes, and every process has the same opportunity to process requests. W hen we provide an 80-port http service, a connection request comes over, and each process is likely to process the connection. F irst, each worker process comes from the master process fork, in which the socket that requires listening is established, and then fork out of multiple worker processes. T he listenfd of all worker processes becomes readable when a new connection comes in, and to ensure that only one process handles the connection, all worker processes grab accept_mutex before registering the listenfd read event, grab the process of the mutually exclusive lock to register the listenfd read event, and call accept to accept the connection in the read event. O nce a worker process is connected, it starts reading the request, parsing the request, processing the request, generating the data, returning it to the client, and finally disconnecting, as is the case with such a complete request. As we can see, a request is handled entirely by the worker process and only in one worker process.
So what are the benefits of Nginx adopting this process model? O f course, the benefits will be many. F irst, for each worker process, a separate process does not require a lock, so it saves the overhead of locking and makes programming and problem finding much easier. S econd, with a separate process, you can leave each other without affecting each other, one process exits, the other processes are still working, the service is not interrupted, and the master process starts a new worker process quickly. O f course, the worker process's abnormal exit, certainly the program has a bug, abnormal exit, will cause all requests on the current worker to fail, but will not affect all requests, so reduce the risk. Of course, there are many benefits, you can slowly experience.
There's a lot about Nginx's process model, so let's look at how Nginx handles events.
Someone might ask, Nginx uses a multi-worker approach to process requests, each worker has only one main thread, that can handle a very limited number of verses ah, how many workers can handle how many verses, why high and high? N o, that's what's so smart about Nginx, which handles requests in an asynchronous, non-blocking way, which means that Nginx can handle thousands of requests at the same time. C onsider the common way apache works (apache also has asynchronous non-blocking versions, but is not commonly used because it conflicts with some of its own modules), and each request has an exclusive worker thread, with thousands of threads processing requests at the same time when the number of companies is in the thousands. This is a big challenge for the operating system, the memory footprint of threads is very large, the cpu overhead of thread context switching is very high, and natural performance is not going up, and these overheads are completely meaningless.
Why can Nginx handle it in an asynchronous non-blocking way, or what's going on with asynchronous non-blocking? L et's go back to the origin and see the full process of a request. F irst, request it, make a connection, then receive the data, receive the data, and then send the data. S Specific to the bottom of the system, is to read and write events, and when read and write events are not ready, it is bound to be inoperable, if you do not use non-blocking way to call, then you have to block the call, the event is not ready, then you can only wait, and so the event is ready, you continue. B locking calls will go into the kernel waiting, cpu will give way to others to use, for a single-threaded worker, obviously not appropriate, when the network events more, everyone is waiting, cpu idle down no one to use, cpu utilization naturally does not go, let alone high and so on. W Well, when you say add the number of processes, what's the difference with apache's threading model, be careful not to add unnecessary context switching. S o, in Nginx, the most taboo blocking system is called. D on't block, it's not blocking. N on-blocking is, the event is not ready, immediately return to EAGAIN, tell you that the event is not ready, you panic what, will come again later. W ell, after a while, check the event again until it's ready, and in the meantime, you can do something else before you see if it's okay. I It's not blocked, but you have to come over from time to time to check the status of the event, and you can do more, but the overhead is not small. T herefore, there is an asynchronous non-blocking event handling mechanism, specific to the system call is like select/poll/epoll/kqueue system call. T They provide a mechanism that allows you to monitor multiple events at the same time, calling them blocked, but you can set a timeout that returns if an event is ready. T his mechanism solves just two of our problems above, taking epoll as an example (in the following example, we use epoll as an example to represent this type of function), when the event is not ready, put it in the epoll, the event is ready, we go to read and write, and when the reading and writing return to EAGAIN, we add it to the epoll again. T That way, whenever an event is ready, we'll deal with it and wait in the epoll only if all the events are not ready. I n this way, we can handle a large number of simultaneous, of course, here's the same request, refers to the unprocessed request, thread only one, so at the same time can handle the request of course only one, just between requests to constantly switch, switching is also because the asynchronous event is not ready, and the initiative to give way. S witching here is at no cost, and you can understand it as looping through multiple prepared events, which is actually the case. T his type of event handling has a great advantage over multithreaded ones, requires no thread creation, uses very little memory per request, has no context switching, and handles events very lightweightly. N o more number of verses will result in unnecessary waste of resources (context switching). M ore synths, just more memory. I 've tested the number of connections before, and on a machine with 24G memory, I've processed more than 2 million requests. Network servers today are basically in this way, which is the main reason why nginx is efficient.
As we said earlier, it is easy to understand here that the number of workers is recommended to set the number of workers to cpu, and that more workers will only cause the process to compete for cpu resources, resulting in unnecessary context switching. M oreover, in order to make better use of the multi-core feature, nginx provides a binding option for cpu affinity, so that we can bind a process to a core so that the cache does not fail because of the process switching. S mall optimizations like this are common in Nginx and illustrate the pain and suffering of Nginx authors. For example, when Nginx compares 4 bytes of strings, it converts 4 characters into an int type and compares them to reduce the number of instructions on the cpu, and so on.
Now you know why Nginx chose such a process model and event model. F or a basic Web server, there are usually three types of events: network events, signals, and timers. A s you know from the explanation above, network events can be solved well by asynchronous non-blocking. How do I handle signals and timers?
First, the processing of the signal. F or Nginx, there are specific signals that represent a specific meaning. T he signal interrupts the program's current operation and continues after changing the state. I f it is a system call, it may cause the system call to fail and need to be re-entered. R egarding the processing of signals, we can learn some professional books, not much to say here. For Nginx, if nginx is waiting for an event (epoll_wait), if the program receives a signal, epoll_wait returns an error after the signal handler has been processed, and then the program can enter the epoll_wait call again.
Also, take a look at the timer. B ecause epoll_wait functions such as the Nginx can set a timeout when called, Nginx uses this timeout to implement the timer. T he timer event inside nginx is placed in a red and black tree that maintains the timer, and each time you enter epoll_wait, you get the minimum time of all timer events from inside the red and black tree and enter epoll_wait after calculating the timeout time of epoll_wait. T herefore, when no event is generated and there is no interrupt signal, epoll_wait timed out, that is, the timer event has arrived. A t this point, nginx checks all timeout events, sets their state to timeouts, and then processes network events. As you can see, when we write Nginx code, the first thing we usually do when dealing with callback functions for network events is to judge timeouts and then deal with network events.
We can summarize Nginx's event handling model with a piece of pseudo-code:
while (true) {
for t in run_tasks:
t.handler();
update_time(&now);
timeout = ETERNITY;
for t in wait_tasks: /* sorted already */
if (t.time <= now) {
t.timeout_handler();
} else {
timeout = t.time - now;
break;
}
nevents = poll_function(events, timeout);
for i in nevents:
task t;
if (events[i].type == READ) {
t.handler = read_handler;
} else { /* events[i].type == WRITE */
t.handler = write_handler;
}
run_tasks_add(t);
}Well, in this section we talk about process models, event models, including network events, signals, and timer events.